
본 포스트는 공룡책이라 불리는 Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 10th』 을 바탕으로 작성하였습니다.
Ch 4. Threads & Concurrency
대부분의 현대 운영체제는 한 프로세스가 다중 스레드를 포함하는 특성을 제공한다.
특히 다중 CPU를 제공하는 최신 다중 코어 시스템에서 스레드 사용을 통한 병렬 처리의 기회를 식별하는 것이 점차 중요해지고 있다.
4.1 Overview
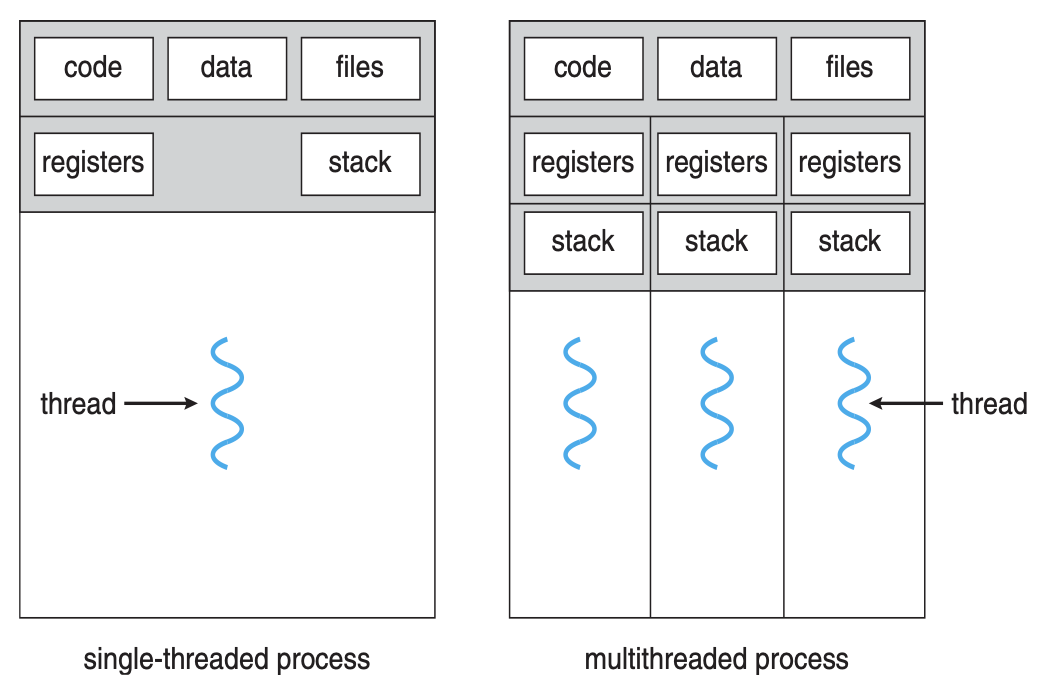
스레드는 CPU 이용의 기본 단위이다. 스레드는 스레드 ID, 프로그램 카운터(PC), 레지스터 집합, 그리고 스택으로 구성된다.
또한 스레드는 같은 프로세스에 속한 다른 스레드와 코드, 데이터 섹션, 열린 파일이나 신호와 같은 운영체제 자원들을 공유한다.
과거 프로세스는 하나의 제어 스레드만을 가지고 있었지만, 현재는 다수의 제어 스레드를 가지며 프로세스는 동시에 하나 이상의 작업을 수행할 수 있다.
* 스레드가 생긴 동기(Motivation)
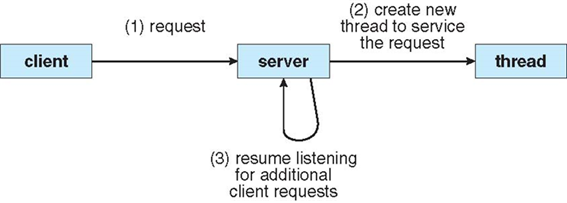
하나의 응용 프로그램이 여러 개의 비슷한 작업을 처리해야 할 상황에서, 만약 웹 서버가 단일 스레드 프로세스로 작동한다면, 한 번에 하나의 클라이언트만 처리할 수 있게 돼서 매우 긴 시간이 걸리게 된다.
이를 위한 방법으로는, 서버에게 서비스 요청이 들어오면, 프로세스는 그 요청을 수행할 별도 프로세스를 생성하는 것이다.
하지만 프로세스 생성 작업은 매우 많은 시간을 소비하고 많은 자원을 필요로 한다.
따라서 대부분은 프로세스 안에 여러 스레드를 만들어 나가는 것이 더 효율적이다.
* 스레드의 장점
1) 응답성
응용 프로그램의 일부분이 봉쇄되거나, 긴 작업을 수행하더라도 프로그램의 수행이 계속되는 것을 허용함으로써, 사용자에 대한 응답성을 증가시킨다.
2) 자원 공유
프로세스는 공유 메모리와 메시지 전달 기법을 통하여만 자원을 공유할 수 있다.
그러나 스레드는 자동으로 그들이 속한 프로세스의 자원들과 메모리를 공유한다.
3) 경제성
스레드는 자신이 속한 프로세스의 자원들을 공유하기 때문에, 스레드를 생성하고 문맥 교환하는 것이 더욱 경제적이다.
또한 문맥 교환은 일반적으로 프로세스 사이보다 스레드 사이에서 더 빠르다.
4) 규모 적응성
다중 프로세서 구조에서 각각의 스레드는 다른 프로세서에서 병렬로 수행될 수 있기 때문에 규모 적응성에서 이점을 갖는다.
4.2 다중 코어 프로그래밍
컴퓨팅 시스템이 발전되면서, 단일 컴퓨팅 칩에 여러 컴퓨팅 코어를 배치할 수 있게 되었다.
각 코어는 운영체제에 별도의 CPU로 보이게 되는데, 이러한 시스템을 다중 코어라고 한다.
이런 다중 코어 시스템 상에서는 시스템이 개별 스레드를 각 코어에 배치할 수 있기 때문에 스레드들이 병렬적으로 실행된다.

* 프로그래밍 도전과제
일반적으로 다중 코어 시스템을 위해 프로그래밍하기 위해서는 극복해야 할 도전 과제가 있다.
1) 태스크 인식(identifying tasks)
Application을 분석하여 separate, concurrent task로 나눌 수 있는 영역을 찾는 작업이 필요하다.
2) 균형(balance)
찾아진 부분들이 전체 작업에 균등한 기여도를 가지도록 태스크로 나누는 것이 중요하다.
3) 데이터 분리(data spliting)
태스크가 접근하고 조작하는 데이터 또한 개별 코어에서 사용할 수 있도록 나누어져야 한다.
4) 데이터 종속성(data dependency)
한 태스크가 다른 태스크로부터 오는 데이터에 종속적인 경우, 프로그래머가 데이터 종속성을 수용할 수 있도록 태스크의 수행을 잘 동기화해야 한다.
* 병렬 실행
일반적으로 데이터 병렬 실행과 태스크 병렬 실행의 두 가지 유형이 존재한다.
데이터 병렬 실행
동일한 데이터의 부분집합을 다수의 계산 코어에 분배한 뒤 각 코어에서 동일한 연산을 실행하는 데 초점을 맞춘다.
예를 들어, 듀얼 코어라면 N개의 데이터에 대해 하나는 0 ~ n/2까지, 나머지는 n/2 + 1 ~ n까지 각 코어에서 병렬로 처리하는 것이다.
태스크 병렬 실행
데이터가 아니라 태스크(스레드)를 다수의 코어에 분배한다. 각 스레드는 고유의 연산을 실행하게 된다.

4.3 다중 스레드 모델
스레드는 두 가지로 나뉘는데, 사용자 수준의 사용자 스레드(user threads), 커널 수준의 커널 스레드(kernel threads)이다.
사용자 스레드는 커널 위에서 지원되며 커널의 지원 없이 관리된다.(이 의미를 잘 이해하셔야 한다!)
반면 커널 스레드는 운영체제에 의해 직접 지원되고 관리된다.
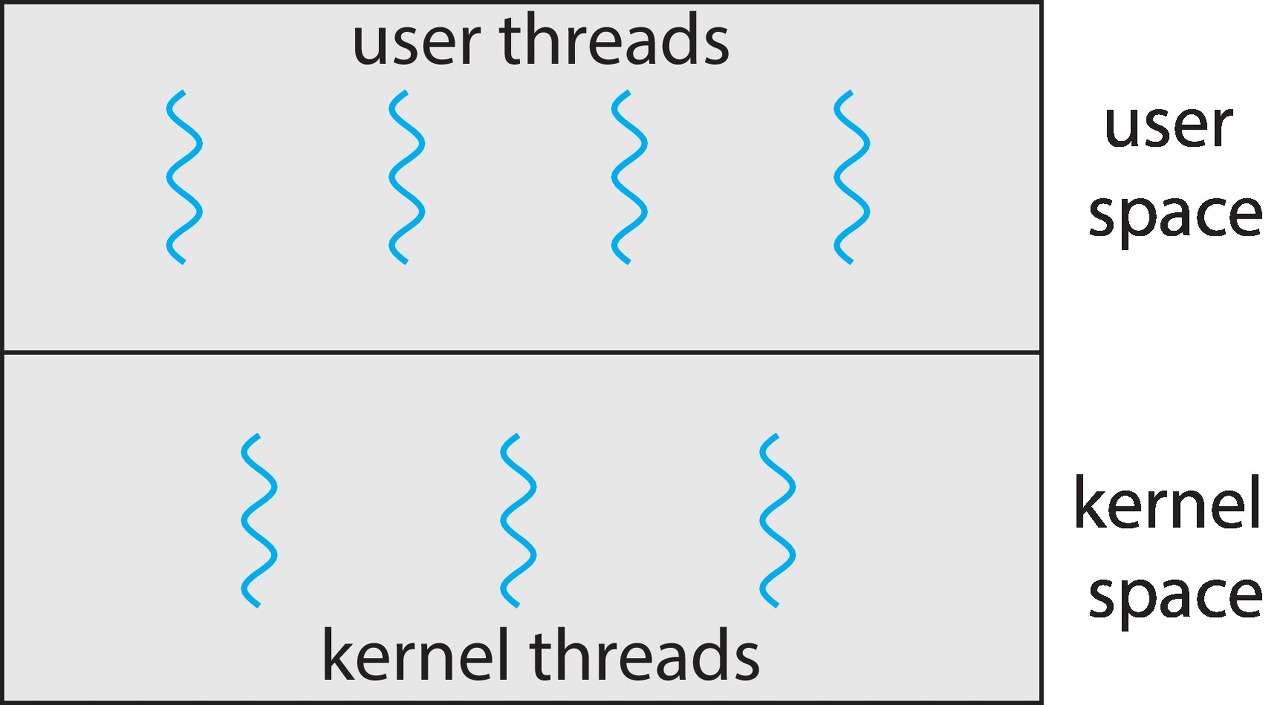
위 그림을 보면 사용자 스레드와 커널 스레드는 어떤 연관 관계가 존재해야 할 것처럼 보인다.
* 다대일 모델(Many-to-One)

다대일 모델은 많은 사용자 스레드를 하나의 커널 스레드로 사상한다. 스레드 관리가 사용자 공간의 스레드 라이브러리에 의해 행해지기 때문에 효율적이라 할 수 있다.
하지만, 한 스레드가 봉쇄형 시스템 콜을 할 경우, 전체 프로세스가 봉쇄되는 등 다중 처리 코어의 이점을 살릴 수 없기 때문에 이 모델을 사용 중인 시스템은 거의 존재하지 않는다.
* 일대일 모델(One-to-One)
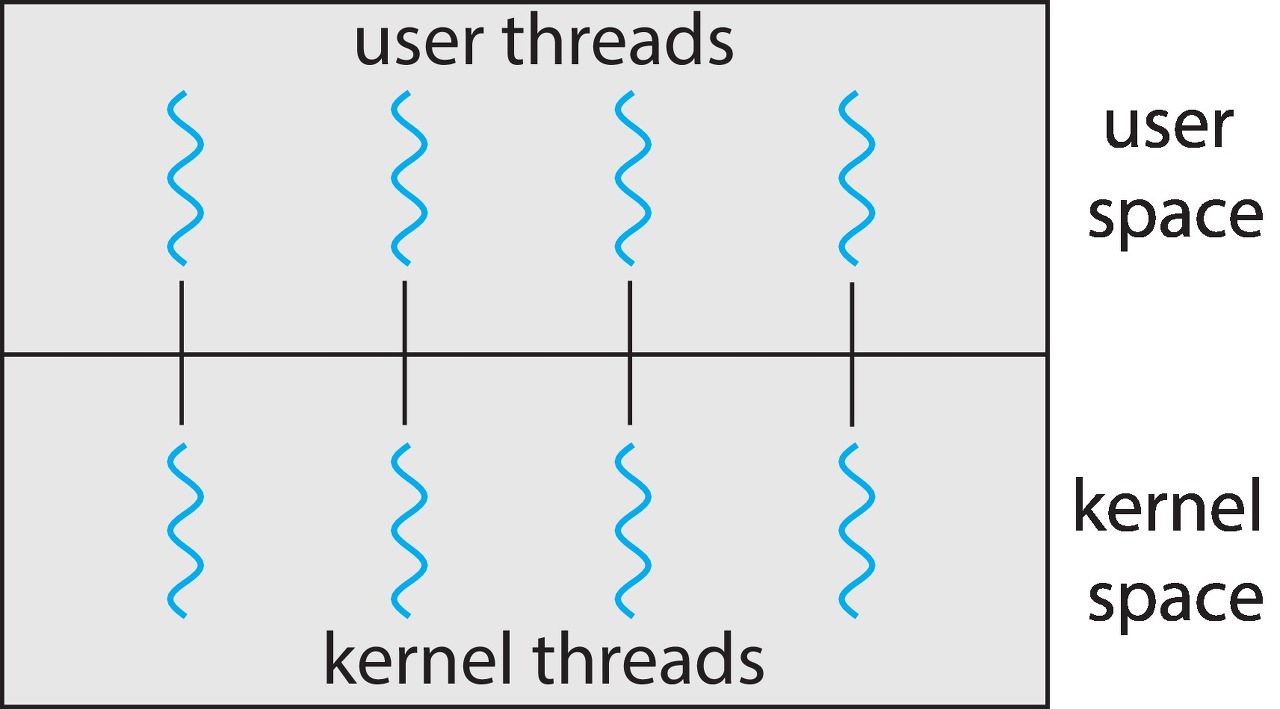
일대일 모델은 각 사용자 스레드를 각각 하나의 커널 스레드로 사상한다.
다대일처럼, 한 스레드가 봉쇄형 시스템 콜을 해도 나머지가 실행될 수 있기 때문에 더 많은 병렬성을 제공한다.
이 모델의 단점은 사용자 스레드를 만들려면 해당 커널 스레드를 만들어야 하며, 많은 수의 커널 스레드가 시스템 성능에 부담을 줄 수 있다는 점이다. Linux, Windows 운영체제는 일대일 모델을 구현한다.
* 다대다 모델(Many-to-Many)

다대다 모델은 여러 개의 사용자 스레드를 그보다 작거나 같은 수의 커널 스레드로 멀티플렉스 한다.
이 모델은 스레드 수가 맞지 않아도 되는, 진정한 병렬성을 제공한다는 점에서 위 두 가지 모델의 문제점을 어느 정도 해결했다.
하지만 실제로 구현하기 매우 어렵기 때문에 대부분의 운영체제는 일대일 모델을 사용한다.
4.4 스레드 라이브러리(Threads Library)
스레드 라이브러리는 프로그래머에게 스레드를 생성하고 관리하기 위한 API를 제공한다.
스레드 라이브러리 구현 방법은 두 가지가 있다.
1. 커널의 지원 없이 완전히 사용자 공간에서만 라이브러리 제공하는 방법
2. 운영체제에 의해 지원되는 커널 수준 라이브러리를 구현하는 방법
현재는 POSIX, Windows, Java 세 종류의 스레드 라이브러리가 주로 사용된다.
스레딩(Threading)에는 2가지 종류가 있다.
비동기 스레딩 (Synchronous)
부모가 자식 스레드를 생성한 후 부모는 자신의 실행을 재개하여 부모와 자식 스레드가 서로 독립적으로 병행하게 실행된다.
스레드가 독립적이기 때문에 스레드 사이의 데이터 공유는 거의 없다.
동기 스레딩 (Asynchronous)
부모 스레드가 하나 이상의 자식 스레드를 생성하고 자식 스레드 모두가 종료할 때까지 기다렸다가 자신의 실행을 재개한다.
통상 동기 스레딩은 스레드 사이의 상당한 양의 데이터 공유를 수반한다.
4.5 암묵적 스레딩
다중 코어 처리의 성장에 따라 수백, 수천 개의 스레드를 가진 Application이 등장하게 되었다.
스레딩의 생성과 관리 책임을 프로그래머로부터 컴파일러와 실행시간 라이브러리에게 넘겨주는 암묵적 스레딩을 사용하면 멀티 스레딩을 효율적으로 활용할 수 있다.
이 방법은 개발자는 병렬 작업만 실행하면 되고 라이브러리가 세부 사항을 결정하는 것이다.
웹 서버는 요청을 받을 때마다 새로운 스레드를 만들어 준다. 하지만 이는 여러 문제가 있다.
첫 번째는, 서비스할 때마다 스레드를 생성하는 데 소요되는 시간이다.
두 번째는 모든 요청마다 새 스레드를 만들어서 서비스해 준다면 최대 스레드 수를 정해야 한다. 무한정 만들면 자원이 고갈되기 때문이다.
이런 문제들을 해결해 줄 수 있는 방법으로 스레드 풀이 있다.
* 스레드 풀(Thread Pool)
기본 아이디어는 프로세스를 시작할 때 아예 일정 수의 스레드들을 미리 풀로 만들어두는 것이다.
스레드 풀은 아래와 같은 장점을 가지게 된다.
- 새 스레드를 만들어 주기보다 기존 스레드로 서비스해 주는 것이 종종 더 빠르다.
- 스레드 풀은 임의 시각에 존재할 스레드 개수에 제한을 둔다. 이러한 제한은 많은 수의 스레드를 병렬 처리할 수 없는 시스템에 도움이 된다.
- 태스크를 생성하는 방법을 태스크로부터 분리하면 태스크의 실행을 유연하게 할 수 있다. (ex. 일정 시간 간격으로)
'학업 > 운영체제' 카테고리의 다른 글
| 공룡책과 함께 OS를 배워보자 6일차 - 동기화 도구 (1) | 2021.08.29 |
|---|---|
| 공룡책과 함께 OS를 배워보자 5일차 - CPU 스케줄링 (2) | 2021.08.13 |
| 공룡책과 함께 OS를 배워보자 3일차 - 프로세스 (0) | 2021.08.13 |
| 공룡책과 함께 OS를 배워보자 2일차 - 운영체제 구조 (0) | 2021.08.13 |
| 공룡책과 함께 OS를 배워보자 1일차 - Overview (0) | 2021.08.13 |