
본 포스트는 공룡책이라 불리는 Abraham Silberschatz, Peter B. Galvin, Greg Gagne의 『Operating System Concept 10th』 을 바탕으로 작성하였습니다.
Ch 3. Process
오늘날 컴퓨터 시스템들은 메모리에 다수의 프로그램을 제어하고, 구획화할 것을 필요로 한다. 이러한 필요성은 프로세스의 개념을 만들었고, 프로세스란 실행 중인 프로그램을 말한다.
프로세스는 현대의 컴퓨팅 시스템에서 작업의 단위이다.
이번 장에서는 프로세스가 무엇인지, 운영체제에서 어떻게 표현되는지 그리고 어떻게 작동하는지에 대해 설명한다.

3.1 프로세스 개념 (Process Concept)
운영체제에 대해 논의할 때 중요한 것 중 하나는 "모든 CPU 활동들을 어떻게 부를 것인가?"이다.
초창기 컴퓨터는 작업(job)을 실행하는 일괄처리 시스템이었고, 사용자 프로그램 또는 태스크(task)를 실행하는 시분할 시스템이 뒤를 이었다. 후에는 다중 태스킹 등을 지원하면서, 운영체제는 메모리 관리와 같은 자체 프로그램된 내부 활동을 지원해야 할 수도 있다.
이러한 모든 활동을 프로세스라고 부를 수 있다.
* 프로세스
프로세스란 실행 중인 프로그램이다.
프로세스의 현재 활동의 상태는 프로그램 카운터(pc) 값과 프로세서 레지스터의 내용으로 나타낸다.
일반적으로 프로세스의 메모리 배치는 여러 구역으로 구분되는데, 이 구역에는 다음이 포함된다.
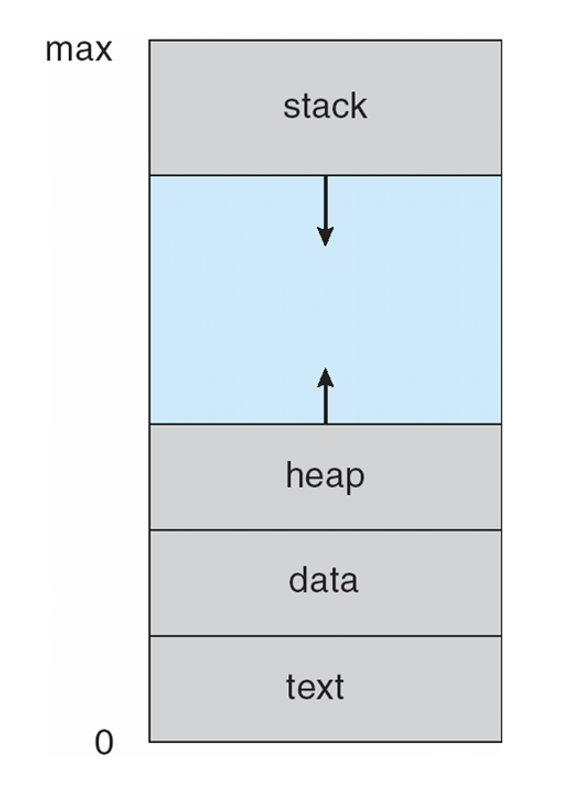
- text : 실행 코드
- data : 전역 변수
- heap : 프로그램 실행 중에 동적으로 할당되는 메모리
- stack : 함수를 호출할 때 임시 데이터 저장장소(ex : 함수 매개변수, 복귀 주소 및 지역 변수)
* 각 영역의 특성
text, data 영역의 크기는 고정되기 때문에 프로그램 실행 시간 동안 크기가 변하지 않는다.
그러나 stack, heap 영역의 크기는 가변적인데,
함수가 호출될 때마다 함수 매개변수, 지역 변수 및 복귀 주소를 포함하는 활성화 레코드(activation record)가 stack에 push 되며, 함수에서 제어가 되돌아오면 stack에서 활성화 레코드가 pop 된다.
마찬가지로 메모리가 동적으로 할당됨에 따라 힙이 커지고, 메모리가 시스템에 반환되면 축소된다.
stack, heap 구역이 서로의 방향으로(위 그림 참조) 커지더라도, 운영체제는 서로 겹치지 않도록 해야 한다.
* 프로그램과 프로세스
프로그램 그 자체는 절대 프로세스가 아니다.
프로그램은 명령어 리스트를 내용으로 가진 디스크에 저장된 파일과 같은 수동적인 존재이다.
이와 달리, 프로세스는 다음에 실행할 명령어를 지정하는 프로그램 카운터와 관련 자원의 집합을 가진 능동적인 존재이다.
실행 파일이 메모리에 적재될 때 프로그램은 프로세스가 된다.
* 프로세스 상태 (Process State)
프로세스는 실행되면서 그 상태가 변한다. 프로세스의 상태는 부분적으로 그 프로세스의 현재의 활동에 따라서 정의된다.
프로세스는 다음 상태 중 하나에 있게 된다.

- new : 프로세스가 생성 중이다.
- running : 명령어들이 실행되고 있다.
- waiting : 프로세스가 어떤 이벤트(입출력 완료 또는 신호의 수신)가 일어나기를 기다린다.
- ready : 프로세스가 처리기에 할당되기를 기다린다.
- terminated : 프로세스의 실행이 종료되었다.
중요한 것은 어느 한순간에 한 프로세서 코어에서는 오직 하나의 프로세스만이 실행된다는 것이다.
하지만 많은 프로세스가 waiting, ready 상태에 있을 수는 있다.
* 프로세스 제어 블록 (Process Control Block)
각 프로세스는 운영체제에서 프로세스 제어 블록(Process Control Block, PCB)에 의해 표현된다.

프로세스 제어 블록은 특정 프로세스와 연관된 여러 정보를 가지고 있으며, 다음을 포함한다.
- 프로세스 상태 : 상태는 new, ready, running, waiting, halted 등이 있다.
- 프로그램 카운터 : 이 프로세스가 다음에 실행할 명령어의 주소를 가리킨다.
- CPU 레지스터들 : 여러 레지스터와 상태 코드 정보를 포함하는데, 이들은 나중에 프로세스가 다시 스케줄 될 때 계속 올바르게 실행되도록 하기 위해서 인터럽트 발생 시 저장되어야 한다.
- CPU 스케줄링 정보 : 프로세스 우선순위, 스케줄 큐에 대한 포인터와 다른 스케줄 매개변수를 포함한다.
- 메모리 관리 정보 : 운영체제에 의해 사용되는 메모리 시스템에 따라 기준(base) 레지스터, 한계(limit) 레지스터의 값, 페이지 테이블, 세그먼트 테이블 등과 같은 정보를 포함한다.
- 회계(accounting) 정보 : CPU 사용 시간과 경과 시간, 시간제한, 계정 번호, 프로세스 번호 등을 포함한다.
- 입출력 상태 정보 : 이 프로레스에 할당된 입출력 장치들과 열린 파일의 목록 등을 포함한다.
* 스레드 (Threads)
위에서 설명한 프로세스 모델은 한 프로세스가 단일의 실행 스레드를 실행하는 프로그램이라 가정하였다.
하지만 현대 운영체제는 한 프로세스가 다수의 실행 스레드를 가질 수 있도록 허용한다. 이러한 특성은 여러 스레드가 병렬로 실행될 수 있다는 것을 의미한다.
3.2 프로세스 스케줄링 (Process Scheduling)
다중 프로그래밍의 목적은 CPU 이용을 최대화하기 위하여 항상 어떤 프로세스가 실행되도록 하는 데 있다.
시분할의 목적은 각 프로그램이 실행되는 동안 사용자가 상호 작용할 수 있도록 프로세스들 사이에서 CPU 코어를 빈번하게 교체하는 것이다.
이 목적을 달성하기 위해 프로세스 스케줄러는 코어에서 실행 가능한 여러 프로세스 중에서 하나의 프로세스를 선택한다.
* 스케줄링 큐
프로세스가 시스템에 들어가면 준비 큐(ready queue)에 들어가서 준비 상태가 되어 CPU 코어에서 실행되기를 기다린다.
이 큐는 일반적으로 연결 리스트로 저장된다.
시스템에는 다른 큐도 존재한다. 프로세스에 CPU 코어가 할당되면 프로세스는 잠시 동안 실행되어 결국 종료되거나, 인터럽트 되거나, I/O 요청의 완료와 같은 특정 이벤트가 발생할 때까지 기다린다. 이런 프로세스들은 대기 큐(wait queue)에 삽입된다.
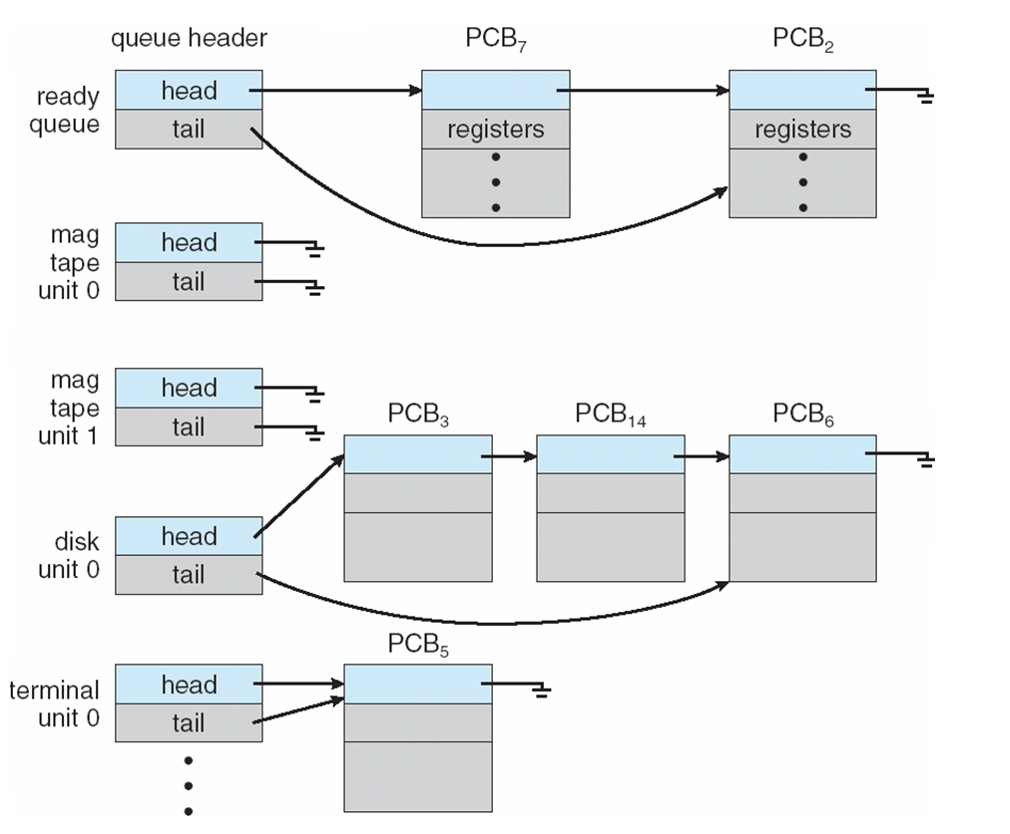
* CPU 스케줄링
프로세스는 수명주기 동안 준비 큐와 다양한 대기 큐를 이동한다.
CPU 스케줄러의 역할은 준비 큐에 있는 프로세스 중에서 선택된 하나의 프로세스에 CPU 코어를 할당하는 것이다.
일부 운영체제는 스와핑으로 알려진 중간 형태의 스케줄링을 가지고 있는데, 핵심 아이디어는 때로는 메모리에서 프로세스를 제거하여 다중 프로그래밍의 정도를 감소시키는 것이 유리할 수 있다는 것이다. 이후 디스크에서 메모리로 "스왑인"하여 상태를 복원할 수 있기 때문에 이 기법을 스와핑이라고 한다. (9장에서 더 자세히 설명 예정)
* 문맥 교환 (Context Switch)
인터럽트는 운영체제가 CPU 코어를 현재 작업에서 뺏어 커널 루틴을 실행할 수 있게 한다.
인터럽트가 발생하면 시스템은 인터럽트 처리가 끝난 후에 문맥을 복구할 수 있도록 현재 실행 중인 프로세스의 문맥을 저장할 필요가 있다.
이 문맥은 프로세스의 PCB에 표현된다.
일반적으로 커널, 사용자 모드 둘 다 CPU의 현재 상태를 저장하는 작업을 수행하고(state save), 나중에 연산을 재개하기 위하여 상태 복구 작업을 수행한다(state restore).
정리하자면, CPU 코어를 다른 프로세스로 교환하려면 이전의 프로세스의 상태를 보관하고 새로운 프로세스의 보관된 상태를 복구하는 작업이 필요하다. 이 작업을 문맥 교환이라 한다.
3.3 프로세스에 대한 연산 (Operation on Processes)
이 장에서는 운영체제가 여러 프로세스를 컨트롤하기 위한 프로세스 생성과 종료를 위한 기법에 대해 다룬다.
* 프로세스 생성
실행 중인 프로세스는 여러 개의 새로운 프로세스들을 생성할 수 있다.
이때, 생성하는 프로세스를 부모 프로세스라고 부르고, 새로운 프로세스는 자식 프로세스라고 부른다. 이 새로운 프로세스들은 각각 다시 다른 프로세스들을 생성할 수 있으며, 그 결과 프로세스의 트리를 형성한다.
현대 운영체제들은 유일한 프로세스 식별자(pid)를 사용하여 프로세스를 구분하는데 이 식별자는 보통 정수이다.

프로세스가 새로운 프로세스를 생성할 때는 두 프로세스를 실행시키는 데 두 가지 방법이 있다.
- 부모는 자식과 병행하게 실행을 계속한다.
- 부모는 일부 또는 모든 자식이 실행을 종료할 때까지 기다린다.
* 프로세스 종료
프로세스가 마지막 문장의 실행을 끝내고, exit 시스템 콜을 사용하여 운영체제에 자신의 삭제를 요청하면 종료한다.
이 시점에서 프로세스는 자신을 기다리고 있는 부모 프로세스에 상태 값을 반환할 수 있다.
또 다른 경우는, 프로세스가 적당한 시스템 콜을 통해서 다른 프로세스의 종료를 유발하는 것이다.
이 경우 시스템 콜은 종료될 프로세스의 부모만이 호출할 수 있다.
부모가 자식의 실행을 종료하는 경우는 다음과 같다.
- 자식이 자신에게 할당된 자원을 초과하여 사용할 때. (이때는 부모가 자식들의 상태를 검사할 수 있는 방편이 주어져야 한다.)
- 자식에게 할당된 태스크가 더 이상 필요 없을 때
- 부모가 exit를 하는데, 운영체제는 부모가 exit 한 후에 자식이 실행을 계속하는 것을 허용하지 않는 경우
3번째의 경우, 보통 부모 프로세스가 종료한 후에 자식 프로세스가 존재할 수 없다. 이 경우 부모가 종료되면 자식도 연달아 종료되는, 연쇄식 종료 작업이 시행된다.
* 좀비와 고아
프로세스가 종료되면 사용하던 자원은 운영체제가 되찾아 간다.
그러나 프로세스의 종료 상태가 저장되는 프로세스 테이블의 해당 항목은 부모 프로세스가 wait()를 호출할 때까지 남아 있게 된다.
좀비
종료되었지만 부모 프로세스가 아직 wait() 호출을 하지 않은 프로세스를 좀비(zombie) 프로세스라고 한다.
종료하게 되면 모든 프로세스는 좀비 상태가 되지만 아주 짧은 시간 동안만 머무른다.
고아
부모 프로세스가 wait()를 호출하지 않고 종료한다면, 자식 프로세스들은 고아(orphan) 프로세스가 된다.
전통적으로 UNIX는 고아 프로세스의 새로운 부모 프로세스로 init 프로세스를 지정함으로써 이 문제를 해결한다.
3.4 프로세스 간 통신 (Interprocess Communication)
운영체제 내에서 실행되는 프로세스들은 독립 또는 협력적인 프로세스 두 가지로 분류된다.
간단히 말해서, 다른 프로세스와 데이터를 공유하면 협력, 그렇지 않으면 독립적인 프로세스라고 한다.
프로세스 협력을 제공하는 이유는 다음과 같다.
- 정보 공유 : 여러 응용 프로그램이 동일한 정보를 요구할 수 있으므로, 병행적 접근 환경을 제공해준다.
- 계산 가속화 : 특정 태스크를 빨리 실행하고 싶다면, 그것을 서브 태스크로 나누어 이들이 각각 다른 서브 태스크들과 병렬로 실행되게 해야 한다.
- 모듈성 : 시스템 기능을 별도 프로세스 또는 스레드들로 나눠 모듈 형식으로 시스템을 구성하길 원한다.
협력적 프로세스들은 데이터를 교환할 수 있는 프로세스 간 통신(interprocess communication, IPC) 기법이 필요하다.
이에 대해서는 기본적으로 공유 메모리(shared memory)와 메시지 전달(message passing) 두 가지 모델이 있다.

공유 메모리
공유 메모리 모델에서는 협력 프로세스들에 의해 공유되는 메모리의 영역이 구축된다. 프로세스들은 그 영역에 데이터를 읽고 쓰고 함으로써 정보를 공유할 수 있다.
메시지 전달
협력 프로세스들 사이에 교환되는 메시지를 통하여 이루어진다.
이 두 가지는 아래에서 좀 더 자세히 다루겠다.
3.5 공유 메모리 시스템에서의 프로세스 간 통신
공유 메모리를 사용하는 프로세스 간 통신에서는 통신하는 프로세스들이 공유 메모리 영역을 구축해야 한다.
공유 메모리 영역은 공유 메모리 세그먼트를 생성하는 프로세스의 주소 공간에 위치한다.
생산자 - 소비자 문제의 해결책으로 공유 메모리를 사용하는데, 생산자와 소비자 프로세스들이 병행으로 실행되도록 하려면, 생산자가 정보를 채워 넣고 소비자가 소모할 수 있는 항목들의 버퍼가 반드시 사용 가능해야 한다. 또 이 버퍼는 공유 메모리 영역에 존재해야 한다.
이때 두 가지 버퍼가 사용되는데, 무한 버퍼는 크기에 실질적인 한계가 없고 유한 버퍼는 버퍼의 크기가 고정되어 있다고 가정한다.
3.6 메시지 전달 시스템에서의 프로세스 간 통신
메시지 전달 방식은 동일한 주소 공간을 공유하지 않고도 프로세스들이 통신을 하고, 그들의 동작을 동기화할 수 있도록 허용하는 기법을 제공한다.
특히 메시지 전달 방식은 네트워크에 연결된 다른 컴퓨터들에도 프로세스가 분산되어있는 경우 유용하다.
* 명명(Naming)
통신을 원하는 프로세스들은 서로를 가리킬 방법이 있어야 한다. 이들은 간접 통신 또는 직접 통신을 사용할 수 있다.
직접 통신
- send(P, message) - 프로세스 P에 메시지를 전송한다.
- receive(Q, message) - 프로세스 Q로부터 메시지를 수신한다.
간접 통신
간접 통신에서는 메일박스(mailbox) 또는 포트(port)로 메시지가 왔다 갔다 한다.
- send(A, message) - 메시지를 메일박스 A로 송신한다.
- receive(A, message) - 메시지를 메일박스 A로부터 수신한다.
* 동기화 (Synchronization)
메시지 전달은 봉쇄형(blocking), 비 봉쇄형(non-blocking) 방식으로 전달된다.
이 두 방식은 각각 동기식, 비동기식이라고도 한다.
- Blocking send : 송신하는 프로세스는 메시지가 수신 프로세스 또는 메일박스에 의해 수신될 때까지 봉쇄된다.
- Non-Blocking send : 송신하는 프로세스가 메시지를 보내고 작업을 재시작한다.
- Blocking receive : 메시지가 이용 가능할 때까지 수신 프로세스가 봉쇄된다.
- Non-Blocking receive : 송신하는 프로세스가 유효한 메시지 또는 null 값을 받는다.
3.7 클라이언트 서버 환경에서 통신
이전까지는 프로세스들 간 통신이라면, 이번에는 클라이언트 서버에서 사용할 수 있는 통신에 대해 알아보겠다.
* 소켓(Socket)
소켓은 통신의 극점(endpoint)을 뜻한다. 두 프로세스가 네트워크상에서 통신을 하려면 각 프로세스 당 하나씩, 총 두 개의 소켓이 필요하다. 각 소켓은 IP 주소와 포트 번호를 결합하여 구별한다.
일반적으로 소켓은 클라이언트 - 서버 구조를 사용한다. 서버는 지정된 포트에 클라이언트 요청 메시지가 도착하기를 기다리게 된다.
요청이 수신되면 서버는 클라이언트 소켓으로부터 연결 요청을 수락함으로써 연결이 완성된다.
*원격 프로시저 호출(Remote Procedure Calls, RPC)
프로세스들이 서로 다른 시스템 위에서 돌아갈 때, 원격 서비스를 제공하기 위해서는 메시지 기반 통신을 해야 한다.
따라서 이전 IPC 방식과 달리 RPC 통신에서 전달되는 메시지는 구조화되어 있고, 데이터의 패킷 수준을 넘어선다.
RPC는 분산 파일 시스템을 구현하는데 유용하다.
'학업 > 운영체제' 카테고리의 다른 글
| 공룡책과 함께 OS를 배워보자 5일차 - CPU 스케줄링 (2) | 2021.08.13 |
|---|---|
| 공룡책과 함께 OS를 배워보자 4일차 - 스레드 (0) | 2021.08.13 |
| 공룡책과 함께 OS를 배워보자 2일차 - 운영체제 구조 (0) | 2021.08.13 |
| 공룡책과 함께 OS를 배워보자 1일차 - Overview (0) | 2021.08.13 |
| 공룡책과 함께 OS를 배워보자 0일차 - 준비 운동 (2) | 2021.08.13 |