https://iceberg.apache.org/spec/?h=deletion+vec
Spec - Apache Iceberg™
Iceberg Table Spec This is a specification for the Iceberg table format that is designed to manage a large, slow-changing collection of files in a distributed file system or key-value store as a table. Format Versioning Versions 1, 2 and 3 of the Iceberg s
iceberg.apache.org
Iceberg v1.8.0부터 생겨난 Deletion Vectors 기능에 대해 살펴봅니다.
탄생 배경
Iceberg는 기존에 다음과 같은 문제점을 겪고 있었습니다.
쓰기 효율(MoR)과 읽기 성능(CoW) 사이의 고질적인 트레이드오프, 그리고 삭제 파일 누적으로 인한 성능 저하 문제
대표적으로 Iceberg의 테이블 버전 2에는 데이터를 업데이트 하거나 삭제하는 Write 과정에서 두 가지 전략을 사용할 수 있습니다.
- Copy on Write (CoW): 새로운 데이터 파일을 만들고, 다음부터 이 버전의 파일을 사용하도록 합니다.
- Merge on Read (MoR): 수정/삭제된 정보만 별도의 삭제 파일에 기록합니다.

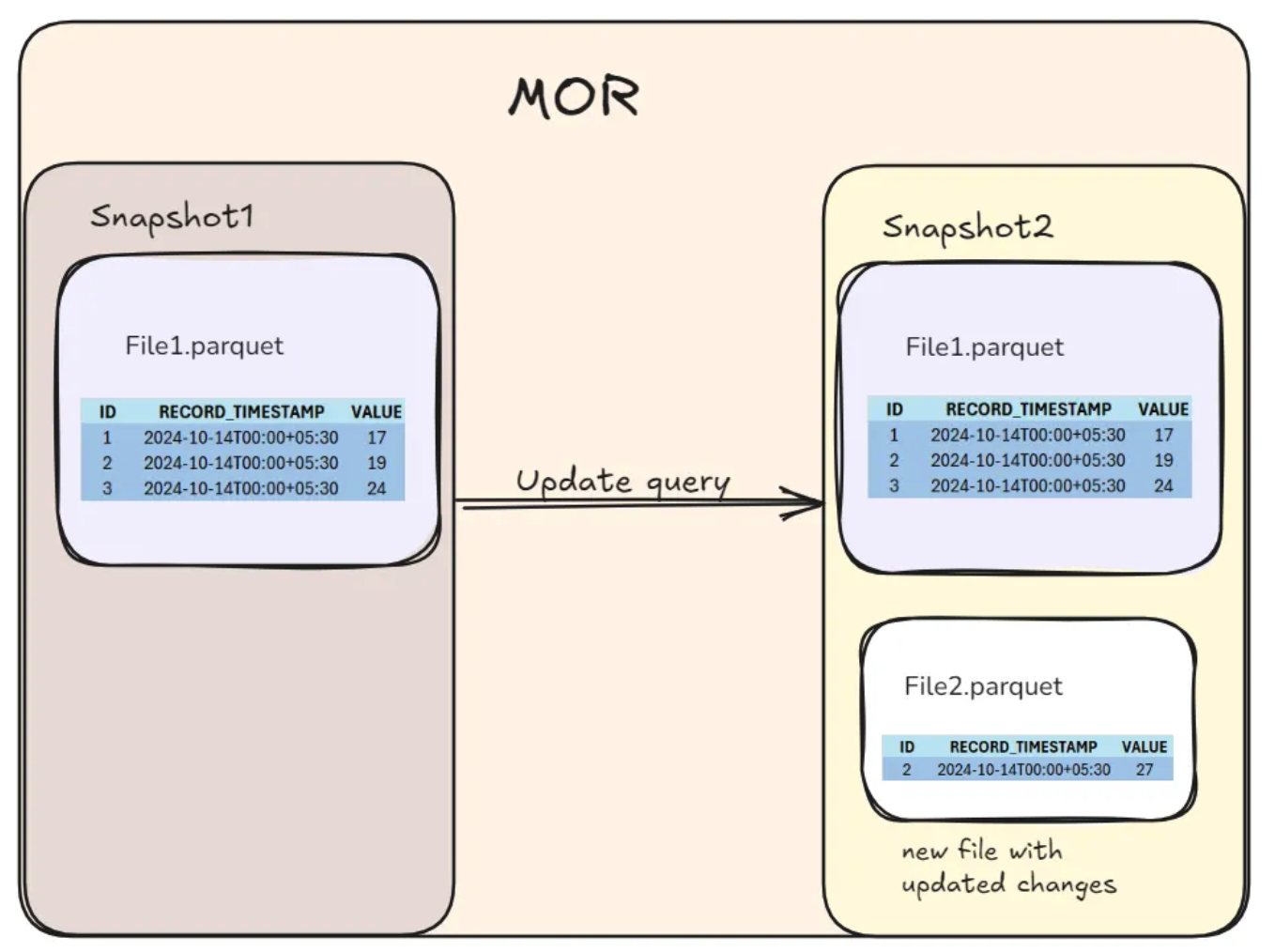
그리고 이 두 전략은 다음과 같은 장단점이 존재합니다.
- CoW
- Write: 새로운 파일을 만드는 것에 대한 오버헤드가 존재합니다. (Bad)
- Read: 그대로 읽기만하면 되므로 매우 빠릅니다. (Good)
- MoR
- Write: 변경된 내용만 기록하면 되므로 쓰기 속도가 매우 빠릅니다. (Good)
- Read: 데이터를 읽을 때 삭제 파일과 비교 과정을 거치므로 오버헤드가 존재합니다. (Bad)
또한 MoR 방식은 삭제 파일을 만든다고 언급했는데요, 이 삭제 파일의 종류는 두 가지가 있습니다.
- Equality delete
- 삭제해야 할 레코드의 PK 값을 저장합니다.
- 예를 들어, id = 100인 행을 모두 삭제 (Upsert와 비슷한 동작 방식)
- 데이터를 읽을 때 모든 레코드를 삭제 파일에 있는 값들과 일일이 비교(Join) 해야 하므로 읽기 성능이 떨어질 수 있습니다.
- Position delete
- 삭제해야 할 데이터의 정확한 위치를 기록합니다.
- 파일의 경로(File Path)와 해당 파일 내의 행 번호(Row Position)를 저장합니다.
- 삭제하려는 데이터가 정확히 어느 파일의 몇 번째 줄에 있는지 먼저 찾아내야하므로 쓰기 시점에 약간의 오버헤드가 발생할 수 있습니다.
이러한 트레이드오프가 있기 때문에 기존의 사용자들은 자신의 프로젝트 특성에 알맞게 CoW, MoR 중 하나를 고르고는 했습니다.
대표적으로 CDC 프로젝트의 경우 실시간으로 파일을 쓰는 연산이 주를 이루기 때문에, Iceberg에 데이터를 적재하는 경우 MoR + Equality delete 방식이 좀 더 적합할 수 있습니다.
여기서 Iceberg는 MoR 방식 중 Position delete 과정을 더 효율적으로 최적화하기 시작합니다.
- Partition-scoped Deletes (AS-IS)
- 특정 파티션 내 데이터가 삭제되면, 해당 파티션에 속한 Position Delete 파일이 생성된다.
- 예를 들어, date=2026-02-07 파티션에 Equality Delete 파일이 생성되면, Iceberg 엔진은 해당 날짜 파티션의 어떤 데이터 파일을 읽더라도 반드시 이 삭제 파일을 불러와서 비교(Join) 해야 합니다.
- File-scoped Deletes (TO-BE)
- Iceberg v1.8.0에 나온 삭제 방식으로, table format 2 설정 시 동작합니다.
- 삭제 파일이 특정 데이터 파일에만 종속되도록 범위를 좁히는 방식입니다.
- 쓰기 시점: 삭제 파일이 어떤 데이터 파일들에 적용되는지 명시 (데이터 파일 A, B, C에 영향)
- 읽기 시점: 데이터 파일 A를 읽을 때, A에 링크를 걸어둔 삭제 파일만 확인합니다.
아무래도 File-scoped 방식이 쓰기 시점에는 조금 느리더라도 삭제 파일을 찾는 과정이 워낙 빠르다 보니 읽기에서 압도적으로 좋습니다.
다만 이 과정도 결국엔 삭제 파일을 생성해야 하며, 삭제 파일 조인의 유혹(?)을 피할 수 없게 됩니다.
Deletion Vectors는 이런 문제를 파일이 아닌 벡터, 비트맵 단위로 해결합니다.
Deletion Vectors
이제는 삭제 파일이 아니라, 삭제 벡터입니다. 본능적으로 일단 더 효율적일 것만 같습니다 😅

Deletion Vector(DV)는 기존의 Position Delete 방식을 훨씬 더 가볍고 빠르게 개선한 방식으로, 삭제된 위치 정보를 파일 형태가 아니라 비트맵(Bitmap) 형태로 압축해서 관리하는 기술입니다.
Deletion Vector의 특징
1. Bitmap을 활용한 초고속 검색
삭제된 행의 위치(Position P)를 0과 1로 이루어진 비트맵에 표시합니다. 예를 들어, 5번째 행이 삭제되었다면 비트맵의 5번 인덱스를 1(Set)로 바꿉니다.
기존 Position Delete 파일은 삭제된 번호 목록을 일일이 읽어서 비교해야 했지만, DV는 메모리 효율이 극도로 높은 Roaring Bitmap을 사용하여 특정 행이 삭제되었는지 즉시(O(1)에 가깝게) 확인할 수 있습니다.
2. Roaring Bitmaps을 사용한 위치 정보 최적화
Roaring Bitmaps은 대규모 데이터 시스템 전반에 사용되는 비트맵 관리 전략입니다.
DV에서는 32비트 Key/Value 분할 방식을 사용합니다. 앞의 32비트는 Key, 뒤의 32비트는 Sub-position으로 나눕니다.
간단히 설명하자면, Key 값은 어느 구역(Bucket)에 속하는가? 를 의미하고, Sub-position은 그 구역 안에서 정확히 몇 번째 행인가?를 결정합니다. 이를 기반으로 매우 큰 숫자를 저장할 때 공간 효율적인 특성을 가집니다.
이 밖에도 여러 최적화 방식이 있지만 이 글에서 전부 소개할 수 없어 아래 참고 페이지를 보시면 좋을 것 같습니다.
참고
Roaring Bitmaps은 그 자체로 상당히 복잡한 방식이지만 빅데이터 처리 전반에 사용되는 방식으로 한 번쯤 확인해 보고 넘어갈 필요가 있습니다. 잘 정리된 문서를 보시는 것을 추천드립니다.
An Introduction to Roaring Bitmaps for Software Engineers
How Roaring Bitmaps improve sets.
machine-learning-made-simple.medium.com
3. Puffin Files
DV는 일반 데이터 파일이 아닌, Iceberg 전용 통계 저장 포맷인 Puffin File 내에 Blob의 형태로 저장됩니다.
기존 MoR 방식에서는 삭제 파일의 형태는 일반적으로 parquet/ORC로 디스크에 저장되어 처리 시 Deserialization 과정을 거쳤는데요, Puffin 파일로 저장할 경우 이러한 변환 과정(Deserialization)이 생략되기 때문에 I/O 효율이 매우 좋아집니다.
또한 기존 Position Delete 방식에서는 데이터 파일 하나에 여러 개의 삭제 파일이 연결될 수 있었습니다. 이런 성향으로 인해 수 많은 삭제 파일이 쌓이면서 I/O 성능을 저하시키는 현상이 발생했습니다.
하지만 Puffin File에는 여러 개의 DV를 넣을 수 있기 때문에 삭제 파일이 과하게 생기는 문제를 해결할 수 있습니다.
4. 데이터 파일 당 최대 하나의 DV
하지만 DV에서는 특정 행에 삭제가 아무리 많이 일어나도, 하나의 데이터 파일에는 논리적으로 최대 한 개의 DV가 생기는 것을 보장합니다.
만약 어떤 데이터 파일에 DV가 쓰였고, 이 데이터 파일에 변화가 일어나면 Bitwise OR 연산을 하기 때문에, 하나의 DV(비트맵)로 관리할 수 있는 것이죠.
이는 삭제 파일 수의 감소뿐만아니라, 로직으로도 데이터 파일을 가져올 때 최대 한 개의 DV만 필터링하면 되므로 꽤나 단순해지는 효과가 있습니다.
정리하자면 Deletion Vectors 방식은 쓰기 및 저장 방식이 복잡해졌지만 읽기/쓰기의 성능 효율이 매우 좋아졌습니다.
- 연산 속도 개선: Bitmap을 활용해 Read/Write 연산 속도가 아주 빨라졌습니다.
- 저장 방식 효율화: Roaring Bitmap으로 저장 방식이 효율적으로 개선되었습니다.
- 디스크 I/O 개선: Puffin 파일 형태로 저장하여 디스크 I/O를 개선할 수 있습니다.
- 삭제 파일 감소 및 일관성 보장: "데이터 파일 당 최대 하나의 DV"라는 일관성을 보장할 수 있습니다.
사용자 입장에서는 데이터가 어떻게 변화되었든 단 하나의 비트맵 필터만 거치면 되기 때문에, MoR 방식임에도 불구하고 CoW에 근접하는 읽기 성능을 낼 수 있게 된 것입니다.
여담
Deletion Vectors의 메인 아이디어는 Iceberg에서 독자적으로 생각한 것이라기 보단, Databricks의 Delta Lake의 아이디어에서 파생된 것이라고 합니다. (참고: Iceberg 공식 유튜브 소개)
참고
https://iceberg.apache.org/puffin-spec/
https://www.youtube.com/watch?v=WqViqjpLsnE