
본 내용은 Computer networking : a top-down approach 책을 바탕으로 정리하였습니다.
Index
- 1. Transport-layer services and protocols
- 2. 다중화와 역다중화
- 3. 비연결 트랜스포트 UDP
- 4. 신뢰적인 데이터 전송의 원칙(rdt)
1. Transport services and protocols
1.1 What's transport layer?
트랜스포트 계층은 앞서 설명한 애플리케이션 계층과, 그다음 장에서 설명할 네트워크 계층 사이에 존재하는
계층으로 이루어진 네트워크 구조의 핵심이다.
트랜스포트 계층 프로토콜은 서로 다른 호스트에서 동작하는 애플리케이션 프로세스들 간의 논리적 통신을 제공한다.
우선 그림을 통해 살펴보자.
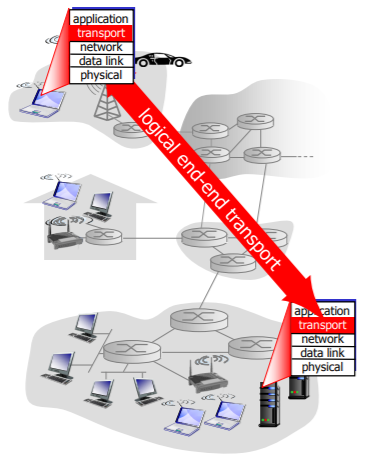
위 그림을 보면 알다시피 트랜스 포츠 계층 프로토콜은 종단 시스템(end system)에서 구현되며
이 곳에서만 존재한다.
1.2 Transport vs network layer
우선 위 그림처럼 트랜스포트 계층은 프로토콜 스택에서 네트워크 계층 바로 상위에 존재한다.
차이점은 트랜스포트 계층 프로토콜은 서로 다른 호스트에서 동작하는 프로세스 사이의 통신을 제공하지만,
네트워크 계층 프로토콜은 호스트들 사이의 논리적 통신을 비교한다.
예를 들자면, 트랜스포트는 아파트 내부의 동, 호수끼리 통신한다면 네트워크는 아파트끼리 통신하는 것이다.
1.3 인터넷 트랜스포트 계층
우리는 앞의 장에서 TCP/IP 네트워크는 애플리케이션 계층에게 두 가지 구별되는 트랜스포트 계층 프로토콜들을 제공한다고 배웠다. 이 둘은 UDP와 TCP이다.
다시 한 번 간단히 복습하자면 TCP는 신뢰적이고 순서가 있는 반면, UDP는 비신뢰적이고 비연결형 서비스를 제공한다.
UDP는 "best-effort delivery service"라고도 하는데, 이는 "최선형 전달 서비스"로 세그먼트를 전달하는 데는 최대한 노력하지만 어떤 보장도 하지 않는다는 것을 의미한다.
또한 우리는 앞에서 애플리케이션 계층이 트랜스포트 계층에게 기대하는 4가지 조건에 대해서 배웠다.
(데이터 무결성, 타이밍, 처리량, 보안)
하지만 TCP는 데이터 무결성(integrity)만 보장했고, 심지어 UDP는 넷 중 아무것도 보장하지 않았다.
2. 다중화와 역다중화
이번에는 프로세스 간의 전달 서비스를 확장하는 개념을 알기 위해, 다중화와 역다중화에 대해서 알아보자.
2.1 개념
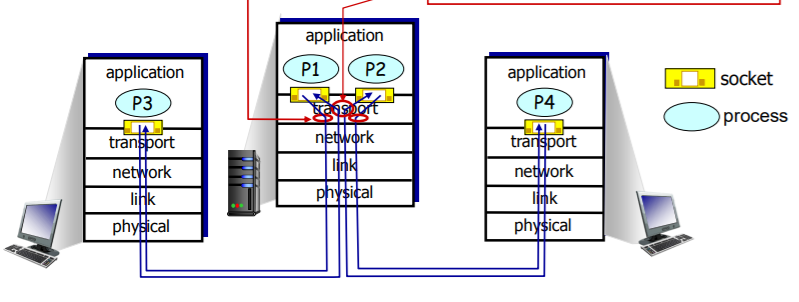
위 그림에서 가운데는 서버, 양 옆은 클라이언트라고 생각해보자.
일단 알아야할 것은 애플리케이션 계층과 트랜스포트 계층 사이에 존재하는 소켓의 역할은
네트워크에서 프로세스로 데이터를 전달하고, 프로세스에서 네트워크로 데이터를 전달하는 출입구 역할을 한다는 것이다. 사실 이 부분이 다중화, 역다중화의 역할과 매우 비슷하다.
1) 다중화
앞서 배운 캡슐화에서 트랜스포트 계층의 역할은 소켓에 세그먼트를 붙이는 작업을 한다고 배웠다.
이는 사실 다중화를 위함인데, 다중화는 각 데이터에 헤더 정보로 캡슐화하고, 그 세그먼트들을 네트워크 계층으로 전달하는 작업을 한다.
위 그림에서 다중화는 서버 프로세스 p1, p2에서 각각 클라이언트에 분배되는 p3, p4로 올바르게 갈 수 있게끔
데이터에 정보를 붙여 아래 계층으로 내보내는 것을 의미한다.
2) 역다중화
역다중화는 다중화와는 반대로 그림의 서버 프로토콜 스택을 기준으로 아래에서 위로 올리는 부분이다.
이때 트랜스포트 계층 세그먼트의 데이터를 올바른 소켓으로 전달하는 작업을 한다.
따라서 p3, p4에서 온 프로세스들을 각각 p1, p2로 옮겨주는 기능을 한다.
2.2 TCP/UDP segment format
위에서는 그냥 올바르게 전달한다~ 아래로 내보낸다~ 는 말만 했는데, 이번엔 도대체 어떤 걸 캡슐화하고, 내보내는지 알아보자.
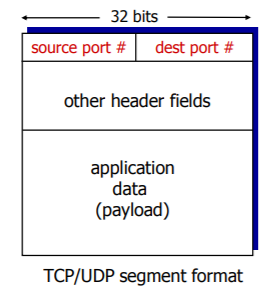
위 그림은 트랜스포트 계층 세그먼트에서의 출발지와 목적지 포트 번호 필드를 보여준다.
포맷의 가로 길이는 32비트로 출발지, 목적지 포트 번호에 각각 16비트(0 ~ 65535)씩 나눠 할당된다.
이 포트 번호들을 활용하는 과정은 이렇다.
- 각 소켓은 포트 번호를 할당받고
- 세그먼트가 호스트에 도착하면 트랜스포트 계층은 세그먼트 안의 목적지 포트 번호를 검사하고
- 이에 상응하는 소켓으로 세그먼트를 보내게 된다.
- 그러면 세그먼트의 데이터는 소켓을 통해 해당되는 프로세스로 전달된다.
2.3 비연결형 다중화와 역다중화
비연결형 즉 UDP 소켓을 이용한 다중화, 역다중화 과정이다.
설명을 돕기위해 UDP 소켓 통신에서 필수적인 코드 두 줄을 소개하자면
- 1. clientSocket = socket(socket.AF_INET, socket.SOCK_DGRAM)
- 2. clientSocket.bind((' ', 19157))
1번은 UDP 소켓을 생성하는 코드로
소켓이 생성될 때 트랜스포트 계층은 포트 번호를 소켓에게 자동으로 할당하고
2번은 소켓 생성뒤에 bind() 함수를 이용하여 특정 포트 번호를 UDP 소켓에 할당하기 위해 추가되는 코드이다.
2번은 옵션처럼 보이지만, 보통 bind 도 함께 쓴다.
코드를 적용시킨 예시를 보자
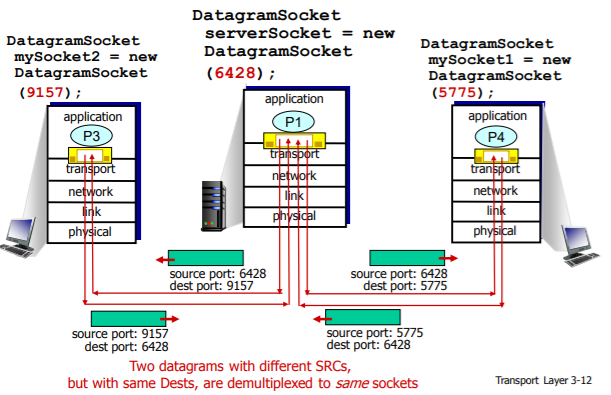
위 그림은 서버에 6428포트, 클라이언트 각각에 대해 9157, 5775 포트 번호를 적용해 소켓을 생성한 그림이다.
앞서 2.1 개념 밑에 있는 그림(뒤에 TCP에서 다시 등장합니다!)과 달리 서로 다른 데이터그램이 들어오는데도 불구하고
UDP에서는 목적지 IP 주소와 목적지 포트 번호가 같으면 2개의 세그먼트(데이터그램 내부의)들은 같은 목적지 소켓을 통해 동일한 프로세스로 향하게 된다. ( + 출발지가 다를지라도)
2.4 연결지향형 다중화와 역다중화
이번엔 TCP 다중화와 역다중화에 대해서 알아볼 것이다.
우선, TCP 소켓과 UDP 소켓의 차이점은 TCP 소켓은 4개 요소들의 튜플 (출발지 IP 주소, 출발지 포트 번호, 목적지 IP 주소, 목적지 포트 번호)에 의해서 식별된다는 것이다.
따라서 TCP 세그먼트가 호스트에 도착하면, 호스트는 해당되는 소켓으로 세그먼트를 전달하기 위해서 4개의 값을 모두 사용한다. (역다중화)
추가로 다른 주소 또는 포트 번호를 가지고 도착하는 TCP 세그먼트는 각기 다른 소켓으로 향하게 된다.
그림을 보고 이해하자

이들은 각각 출발지 - 목적지 간의 연결이 튜플 값에 따라 모두 다르게 되어있기 때문에
원하고자 하는 도착지에 세그먼트들을 옮길 수 있게 된다.
이러한 결과로 TCP의 연결 보장성을 확인할 수 있다.
3. 비연결형 트랜스포트 UDP
이번엔 트랜스포트 계층에서 UDP가 동작하는 과정을 자세히 살펴보겠다.
그 전에 UDP segment의 특징을 좀 더 자세히 보면
앞에서 계속 UDP의 특성 중 best-effort 라는 말이 나왔는데, 이 말은 UDP segment 가 갑자기 사라질수도 있고 전달 순서가 뒤바뀔 수 있다는 것을 의미한다.(1대1로 연결된게 아니기때문)
또한 이런 비연결형 특성때문에 handshaking 과정도 필요없게 된다.
3.1 UDP segment header
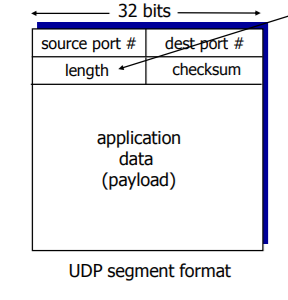
아까 위에서 봤던 UDP/TCP segment format에서 header field를 자세히 들여다본 그림이다.
UDP의 헤더 필드에는 length, checksum이 있다.
- length : UDP segment의 길이이며, 그림상 16비트지만 단위가 바이트이기 때문에 2^16= 약 65535 바이트라고 봐야 한다! 따라서 64KB이고 이 크기가 UDP 세그먼트가 보낼 수 있는 크기이다.
- checksum : 에러를 판별하기 위한 부분으로 바로 밑에서 자세히 설명하겠다.
3.2 UDP checksum
UDP 체크섬은 오류 검출을 제공한다. 즉 체크섬은 세그먼트가 출발지로부터 목적지로 이동했을 때
UDP 세그먼트 안의 비트에 대한 변경사항이 있는지 검사하는 것이다.
송신 측에서 UDP는 세그먼트 안에 있는 모든 16비트 워드를 더하고 이에 대하여 다시 1의 보수를 수행한다.
예를 들어, 다음과 같은 3개의 16비트 워드가 있다고 하자.
0110011001100000 -- 1
0101010101010101 -- 2
1000111100001100 -- 3
1과 2의 합은 다음과 같다
0110011001100000 -- 1
0101010101010101 -- 2
1011101110110101 -- 1 + 2
이에 3을 더한 값은 다음과 같다.
1011101110110101 -- 1 + 2
1000111100001100 -- 3
0100101011000010 -- 1 + 2 + 3
1과 1이 만나면 다음 자릿수로 넘어가는데, 자세히 보면 가장 왼쪽 비트는 갑자기 사라져 버렸다.
이는 오버플로우가 발생하여 가장 오른쪽 비트에 +1이 된 것이다.
다음은 1의 보수 과정이다. 합의 1의 보수는 다음과 같다.
0100101011000010 -- 1 + 2 + 3
1011010100111101 -- 합의 1의 보수
모든 1을 0으로, 0을 1로 바꾸면 되며 이것이 체크섬이된다.
따라서 체크섬을 포함한 4개의 비트를 더하면 값은 11111111111이 될 것이다.
이렇게 모든 비트가 1로 채워졌다면, 패킷에 오류가 없는 것이고
하나라도 0이 있다면 패킷에 오류가 발생했음을 알 수 있다.
4. 신뢰적인 데이터 전송의 원칙(rdt)
이번장에서 가장 이해하기도, 설명하기도 어려운 부분이다.
이번 장에서는 하위 채널 모델에서부터 신뢰적인 데이터 전송 프로토콜의 송신자, 수신자 측면을
점점 개발해나가면서 발생하는 오류들을 처리해나갈 예정이다.
자세한 설명에 앞서, 한 가지 가정과 용어들을 정리하자면
먼저 한 가지 가정은, 보내어지는 패킷들이 순서대로 전달된다는 것이다.
패킷의 순서를 바꾸지 않고 데이터의 흐름대로 설명할 것이다.
또한 용어들은 각각
- rdt_send() : 프로토콜의 송신 측은 이 호출에 의해 위의 계층에 의해서 호출이 된다.(call : 위에서 아래로)
- rdt_rcv() : 패킷이 채널의 수신 측으로부터 도착했을 때 호출된다.(callback: 아래에서 위로)
- deliver_data() : 수신자 측이 데이터를 반대로 넘길 때 호출된다.
- udt_send() : 비신뢰적인 데이터 전송(unreliable data transfer)으로서, 송신, 수신 측이 패킷을 양방향으로 전달할 때 사용될 것이다.
4.1 기본 그림

rdt 설명에 앞서 기본이 되는 그림을 하나 가져왔다.
이 그림은 FSM(유한 상태 머신)이며 화살표는 단방향(unidirectional)으로 동작하게 된다.
이 FSM에는 3가지 요소가 있는데 각각 state, event, actions이다.
- state : 각각 동그라미를 노드라고 보면, 노드 안에 쓰여 있는 글자들이다. 다음 이벤트를 결정하는 중요한 요소다.
- event : 전송이 일으키는 사건을 의미한다.
- actions : 이벤트가 발생될 시 취하는 행동을 뜻한다.
따로따로 설명하면 이해가 안 될 것 같아 먼저 설명하느라 서론이 길어졌는데, 이제 본격적으로 rdt에 대해 알아보도록 하자.
4.2 rdt 1.0 - 완전하게 신뢰적인 채널에서의 프로토콜
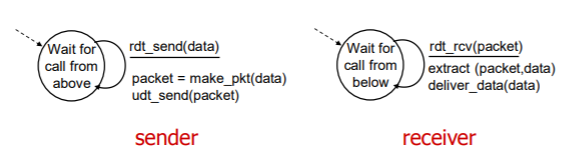
가장 이상적인 프로토콜로, 단순하며 따로 예외 처리해주지 않아도 된다.
하지만 이상일뿐 실제로는 존재하지 않는 프로토콜이다.
과정(sender)
- 1. 위에서부터 호출을 기다린다. (state)
- 2. rdt_send(data)로 상위 계층으로부터 데이터를 받아들인다. (event)
- 3. make_pkt(data) 데이터를 포함한 패킷을 생성한다. (actions)
- 4. udt_send(packet) 패킷을 채널로 송신한다. (event)
과정(receiver)
- 1. rdt_rcv(packet) 하위의 채널로부터 패킷을 수신한다. (event)
- 2. extract(packet, data) 데이터를 추출한다.
- 3. deliver_data(data) 데이터를 상위 계층으로 전달한다.
장점
- 오류가 생길 수 없어 수신 측이 피드백을 제공할 필요가 없다.
- 패킷 손실이 일어나지 않는다.
4.3 rdt 2.0 : 비트 오류가 있는 채널 상에서의 신뢰적 데이터 전송
rdt 2.0 은 비트 오류에 대한 해결책으로 재전송(retransmission)을 제시한다.
재전송을 하려면 수신자가 잘 받았는지 못 받았는지 말을 해줘야 알 수 있는데 rdt2.0에서는 수신 측의 피드백을 통해 이를 처리한다.
수신 측의 피드백
수신자는 ACKs 또는 NAKs를 송신 측에 전달하는데
ACKs는 잘 받았다는 의미이고, NAKs는 비트 에러가 발생했다는 의미이다.
1) rdt 2.0 : 에러가 발생하지 않는 상황에서의 작동
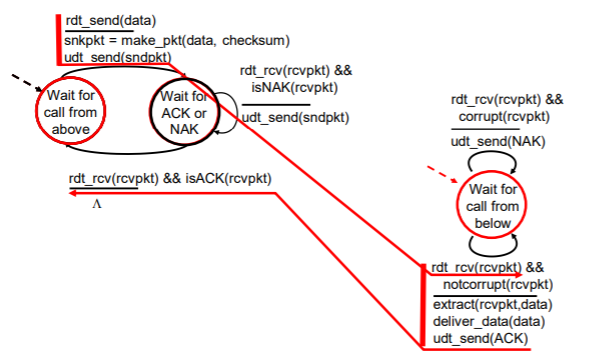
좌측이 sender, 우측이 receiver에 해당한다.
왼쪽 밑에 V를 거꾸로 뒤집은 모양은 이벤트가 발생했을 때, 아무런 액션도 취하지 않는 상태를 말한다.
과정(sender)
- 1. 위에서부터 호출을 기다린다. (state)
- 2. rdt_send(data)로 상위 계층으로부터 데이터를 받아들인다. (event)
- 3. make_pkt(data) 데이터를 포함한 패킷을 생성한다. (actions)
- 4. udt_send(packet) 패킷을 채널로 송신한다. (event)
- 5. isACK(rcvpkt) : ACK 피드백이 왔는지 확인한다.
과정(receiver)
- 1. rdt_rcv(packet) 하위의 채널로부터 패킷을 수신한다. (event)
- 1. notcorrupt(rcvpkt) 수신한 패킷의 손상 여부를 확인한다.
- 2. extract(packet, data) 데이터를 추출한다.
- 3. deliver_data(data) 데이터를 상위 계층으로 전달한다.
- 4. udt_send(ACK) ACK 피드백을 sender에 전달한다.
2) rdt 2.0 : 에러 시나리오
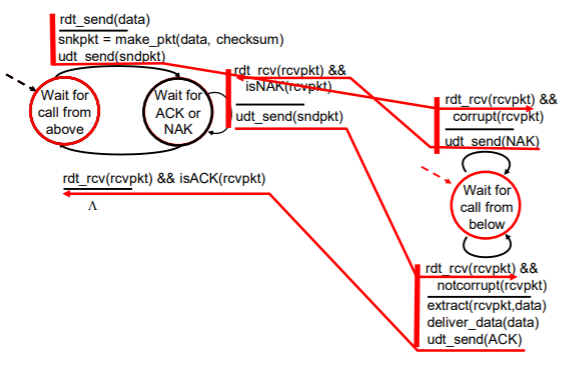
이번엔 에러가 발생해 NAK를 보내는 경우 과정이다.
과정(sender)
- 1. 위에서부터 호출을 기다린다. (state)
- 2. rdt_send(data)로 상위 계층으로부터 데이터를 받아들인다. (event)
- 3. make_pkt(data) : 데이터를 포함한 패킷을 생성한다. (actions)
- 4. udt_send(packet) : 패킷을 채널로 송신한다. (event)
- 5. isNAK(rcvpkt) : NAK 피드백이 왔는지 확인한다.
- 6. udt_send(sndpkt) : NAK 피드백이 왔으므로 재전송한다.
과정(receiver)
- 1. rdt_rcv(packet) 하위의 채널로부터 패킷을 수신한다. (event)
- 1. corrupt(rcvpkt) 수신한 패킷의 손상 여부를 확인한다.
- 2. udt_send(NAK) : 패킷이 손상되어 NAK 피드백을 보낸다.
- 3. rdt_rcv(rcvpkt) : 재전송된 패킷을 받는다.
- 4. extract(packet, data) 데이터를 추출한다.
- 5. deliver_data(data) 데이터를 상위 계층으로 전달한다.
- 6. udt_send(ACK) ACK 피드백을 sender에 전달한다.
위와 같은 과정은 고정된 과정이 아니라 여러 번 반복될 수도 있다!
4.4 rdt 2.0의 치명적인 에러들
- 애초에 ACK/NAK 피드백들이 손상된 경우 sender는 알 수 없다.
- 따라서 sender가 손상된 피드백들을 잘못 이해하여 재전송한 경우, 명령이(action) 복제될 가능성이 있다.
해결책 : 데이터 패킷에 새로운 필드를 추가하고 이 필드 안에 순서 번호를 삽입한다.
결과 : 순서 번호를 보고, 재전송된 것인지 새로운 패킷을 전송한 것인지 알 수 있다.
4.5 rdt 2.1
rdt 2.0의 수정된 버전이다.
rdt 2.1의 FSM은 전보다 두 배 많은 상태를 가지고 있는데, 이는 전송되거나 기다리고 있는 패킷이
순서 번호 0 또는 1을 가져야 하는지 반영해야 하기 때문이다.
순서 번호가 0 또는 1밖에 없는 이유는 두 가지 수만 반복해도 최근과 이전 패킷을 구분할 수 있기 때문이다.
1) rdt 2.1 sender's FSM
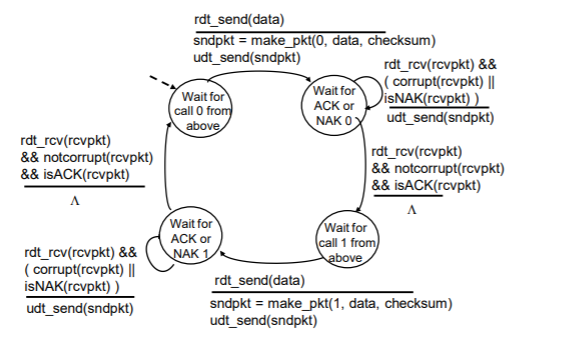
rdt 2.1의 FSM 그림이다. 2.0 버전과 달라진 점을 몇 가지 소개하자면
- 패킷에 0 또는 1이 추가되었다.(시퀀스 넘버)
- 상태가 2배 늘어났고, 이들은 각각 0 또는 1을 기다린다.
2) rdt 2.1 receiver's FSM
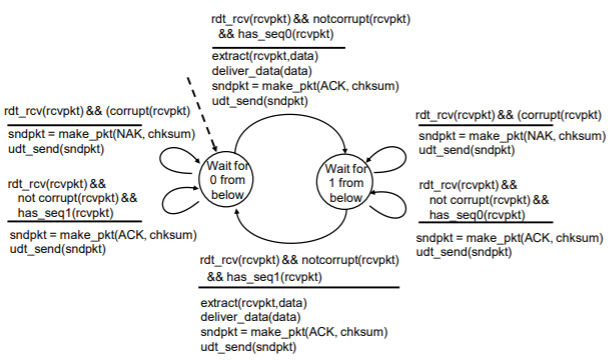
- has_seq# 함수가 추가되었다.
- 순서가 바뀐 패킷이 수신되면 수신자는 이미 전에 수신한 패킷에 대한 긍정 확인 응답을 전송한다.
- 수신자 FSM에서 make_pkt 함수에 chksum 인자가 추가되었는데, 이는 ACK 또는 NAK가 깨졌는지 여부를 송신자에게 알려준다.
이번엔 패킷이 복제되는 상황만 살펴보자면
- 1. 송신자가 데이터를 보냄
- 2. 수신자가 패킷을 잘 받았고, ACK 를 보냈으나 전송과정에서 NAK로 바뀌어버림 -> 이 상황에서 수신자는 seq1 을 기다리게끔 상태가 바뀌어짐
- 3. 송신자는 NAK를 받아서 다시 재전송하나, 수신측에서 seq가 안맞는걸 알고 바로 ACK를 보내줌
- 4. 송신자는 ACK가 왔으니 다음 상태로 이동
4.6 rdt 2.2 : a NAK-free protocol
rdt 2.2 버전은 rdt 2.1 버전에서 NAK을 사용하지 않은 프로토콜이다.
어떻게 NAK을 사용하지 않느냐면.. NAK 대신에 그 전 패킷에 대한 ACK을 보내는 것이다.
기존에 지금 패킷에 대한 NAK을 보내 재전송을 처리했다면, 지금은 그 전 패킷에 대해 ACK을 보내
수신자가 "저는 여기까지만 알아들었습니다!" 하고 그 이후의 패킷을 보내라는 의미이다.
rdt2.2의 FSM은 2.1 버전에서 NAK을 보내거나 확인하는 부분을 그 전 패킷에 대해 ACK을 보내거나,
현재 와야 할 ACK 번호가 올바르게 왔는지 체크하면 된다.
4.7 rdt 3.0 : channels with errors and loss
이전까지의 rdt 버전들은 비트 에러에 대해서만 처리했지, 패킷이 아예 유실되는 경우에 대해서는 처리하지 않았다.
만약 ACK이 유실되어 오지 않았다면, 송신자는 뭘 보내야 할지 도무지 알 수가 없다.
그래서 패킷이 손실되지 않고 제대로 갔는지 타이머를 통해 확인해야 하는데, 이 기법을 타임 아웃이라고 한다.
rdt 3.0 FSM sender

이번 FSM은 timer가 추가되었다.
타이머의 동작은 다음과 같다.
- 1. 패킷을 송신하는 시간에 타이머를 시작(송신측에서)
- 2. 만약 ACK가 오기 전에 타이머가 끝나면 재전송
- 3. ACK가 왔다면 타이머를 멈춤
하지만 패킷이 유별나게 큰 지연 시간을 가진다면 데이터 패킷이나 그 패킷에 대한 ACK가 손실되지 않았다 하더라도 패킷을 재전송할 수 있다. 이것은 송신자 - 수신자 채널에서 중복 데이터 패킷(duplicate)의 가능성을 포함한다.
하지만 우리는 이미 rdt 2.2에서 sequence number를 통해 중복되는 경우를 처리할 수 있다.
rdt 3.0 은 기능적으로 정확한 프로토콜이다.
하지만 이 프로토콜 역시 패킷을 하나하나 보내기 때문에 전송시간(RTT)의 문제가 있다!
4.9 Pipelined protocols
파이프 라인 프로토콜은 마치 송신자와 수신자 사이에 파이프를 연결하여, 송신자가 여러 개의 패킷을 마치 비행기를 타고 날아가는 것처럼 보내게 된다.
이 경우 여러 개의 패킷을 동시에 보내기 때문에 sequence number를 0과 1 뿐 아니라 여러개로 늘려야 하며
여러개의 패킷을 담을 수 있게 버퍼를 만들어 주어야 한다. 하지만 전송시간이 매우 빠르다.
보통 파이프라인 프로토콜은 두 가지 형태가 있는데, go-back-N과 selective repeat 기법이다.
1) go-back-N(GBN) : N부터 반복
GBN 프로토콜에서 송신자는 확인 응답을 기다리지 않고, 여러 패킷을 전송할 수 있다.
하지만 조건이 있다. 파이프라인에서 확인 응답이 안 된 패킷의 최대 허용 수 N보다 크지 않아야 한다는 점이다.
특징
- 송신자는 확인응답이 되지 않은 N개의 패킷을 파이프라인 안에서 가질 수 있다.
- 수신자는 받은 패킷들에 대해서 마지막 패킷에 대해서만 ACK를 보낸다.(누적 ack)
- 송신자는 가장 오래된 '전송되었지만 아직 확인 응답 오지 않은 패킷'에 대한 타이머만 사용한다.
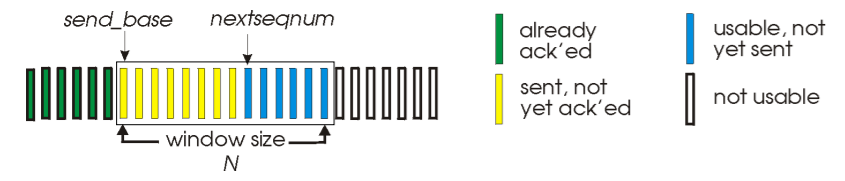
GBN 프로토콜은 위 그림과 같이 직사각형의 윈도를 가진다. 이를 슬라이딩 윈도라고 한다.
가장 오래된 패킷의 순서 번호를 send_base로 정의하고, 사용되지 않은 가장 작은 순서번호를 nextseqnum으로 정의한다면, 순서 번호의 범위에서 4가지 패킷을 식별할 수 있다.
- 1. 이미 확인 응답받은 패킷
- 2. 전송하였지만, 아직 확인 응답받지 않은 패킷
- 3. 사용 가능하지만 아직 전송하지 않은 패킷
- 4. 사용할 수 없는 패킷
GBN의 중요한 특징
- 만약 base 패킷이 아닌 이후의 패킷에 대한 ack 응답이 먼저 왔다면, 그 이전의 패킷들은 모두 ack 처리한다.
- 만약 패킷 n+1이 먼저 도착했고, n이 수신되었는데 n이 손실되었다면(타임 아웃도 포함) n이상의 패킷들은 모두 재전송해야 한다.
2) Selective repeat : 선택적 반복
앞서 설명한 GBN의 특성 중 이전 패킷에 대한 손실이 발생하면, 쓸데없이 다른 패킷들도 재전송한다는 불필요한 액션을 한다는 것을 배웠다.
선택적 반복은 이러한 GBN의 단점을 보완한 프로토콜로, 오류가 발생한 패킷만을 송신자가 다시 전송함으로써
불필요한 재전송을 피한다.
문제점
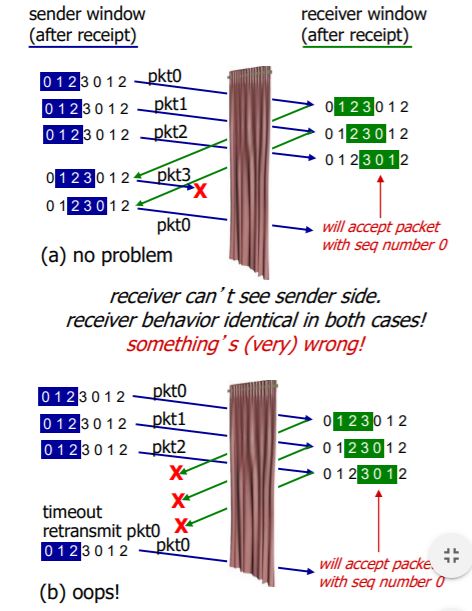
위 그림처럼 만약 시퀀스 넘버가 3가지로 이루어져 있고, 윈도 크기가 3이라면
전송 중에 같은 시퀀스 넘버가 동시에 움직일 경우, 송수신자에게 혼란을 야기할 수 있다.
따라서 시퀀스 넘버는 적어도 윈도 크기의 2배는 넘어야 이 문제를 해결할 수 있다.
'Computer Network' 카테고리의 다른 글
| 7. TCP 혼잡제어 (0) | 2020.06.04 |
|---|---|
| 6. TCP - transport's view (0) | 2020.06.03 |
| 4. P2P, video streaming (0) | 2020.05.29 |
| 3. FTP, electronic mail, DNS (0) | 2020.05.28 |
| 2. application layer (2) | 2020.05.27 |
본 내용은 Computer networking : a top-down approach 책을 바탕으로 정리하였습니다.
Index
- 1. Transport-layer services and protocols
- 2. 다중화와 역다중화
- 3. 비연결 트랜스포트 UDP
- 4. 신뢰적인 데이터 전송의 원칙(rdt)
1. Transport services and protocols
1.1 What's transport layer?
트랜스포트 계층은 앞서 설명한 애플리케이션 계층과, 그다음 장에서 설명할 네트워크 계층 사이에 존재하는
계층으로 이루어진 네트워크 구조의 핵심이다.
트랜스포트 계층 프로토콜은 서로 다른 호스트에서 동작하는 애플리케이션 프로세스들 간의 논리적 통신을 제공한다.
우선 그림을 통해 살펴보자.
위 그림을 보면 알다시피 트랜스 포츠 계층 프로토콜은 종단 시스템(end system)에서 구현되며
이 곳에서만 존재한다.
1.2 Transport vs network layer
우선 위 그림처럼 트랜스포트 계층은 프로토콜 스택에서 네트워크 계층 바로 상위에 존재한다.
차이점은 트랜스포트 계층 프로토콜은 서로 다른 호스트에서 동작하는 프로세스 사이의 통신을 제공하지만,
네트워크 계층 프로토콜은 호스트들 사이의 논리적 통신을 비교한다.
예를 들자면, 트랜스포트는 아파트 내부의 동, 호수끼리 통신한다면 네트워크는 아파트끼리 통신하는 것이다.
1.3 인터넷 트랜스포트 계층
우리는 앞의 장에서 TCP/IP 네트워크는 애플리케이션 계층에게 두 가지 구별되는 트랜스포트 계층 프로토콜들을 제공한다고 배웠다. 이 둘은 UDP와 TCP이다.
다시 한 번 간단히 복습하자면 TCP는 신뢰적이고 순서가 있는 반면, UDP는 비신뢰적이고 비연결형 서비스를 제공한다.
UDP는 "best-effort delivery service"라고도 하는데, 이는 "최선형 전달 서비스"로 세그먼트를 전달하는 데는 최대한 노력하지만 어떤 보장도 하지 않는다는 것을 의미한다.
또한 우리는 앞에서 애플리케이션 계층이 트랜스포트 계층에게 기대하는 4가지 조건에 대해서 배웠다.
(데이터 무결성, 타이밍, 처리량, 보안)
하지만 TCP는 데이터 무결성(integrity)만 보장했고, 심지어 UDP는 넷 중 아무것도 보장하지 않았다.
2. 다중화와 역다중화
이번에는 프로세스 간의 전달 서비스를 확장하는 개념을 알기 위해, 다중화와 역다중화에 대해서 알아보자.
2.1 개념
위 그림에서 가운데는 서버, 양 옆은 클라이언트라고 생각해보자.
일단 알아야할 것은 애플리케이션 계층과 트랜스포트 계층 사이에 존재하는 소켓의 역할은
네트워크에서 프로세스로 데이터를 전달하고, 프로세스에서 네트워크로 데이터를 전달하는 출입구 역할을 한다는 것이다. 사실 이 부분이 다중화, 역다중화의 역할과 매우 비슷하다.
1) 다중화
앞서 배운 캡슐화에서 트랜스포트 계층의 역할은 소켓에 세그먼트를 붙이는 작업을 한다고 배웠다.
이는 사실 다중화를 위함인데, 다중화는 각 데이터에 헤더 정보로 캡슐화하고, 그 세그먼트들을 네트워크 계층으로 전달하는 작업을 한다.
위 그림에서 다중화는 서버 프로세스 p1, p2에서 각각 클라이언트에 분배되는 p3, p4로 올바르게 갈 수 있게끔
데이터에 정보를 붙여 아래 계층으로 내보내는 것을 의미한다.
2) 역다중화
역다중화는 다중화와는 반대로 그림의 서버 프로토콜 스택을 기준으로 아래에서 위로 올리는 부분이다.
이때 트랜스포트 계층 세그먼트의 데이터를 올바른 소켓으로 전달하는 작업을 한다.
따라서 p3, p4에서 온 프로세스들을 각각 p1, p2로 옮겨주는 기능을 한다.
2.2 TCP/UDP segment format
위에서는 그냥 올바르게 전달한다~ 아래로 내보낸다~ 는 말만 했는데, 이번엔 도대체 어떤 걸 캡슐화하고, 내보내는지 알아보자.
위 그림은 트랜스포트 계층 세그먼트에서의 출발지와 목적지 포트 번호 필드를 보여준다.
포맷의 가로 길이는 32비트로 출발지, 목적지 포트 번호에 각각 16비트(0 ~ 65535)씩 나눠 할당된다.
이 포트 번호들을 활용하는 과정은 이렇다.
- 각 소켓은 포트 번호를 할당받고
- 세그먼트가 호스트에 도착하면 트랜스포트 계층은 세그먼트 안의 목적지 포트 번호를 검사하고
- 이에 상응하는 소켓으로 세그먼트를 보내게 된다.
- 그러면 세그먼트의 데이터는 소켓을 통해 해당되는 프로세스로 전달된다.
2.3 비연결형 다중화와 역다중화
비연결형 즉 UDP 소켓을 이용한 다중화, 역다중화 과정이다.
설명을 돕기위해 UDP 소켓 통신에서 필수적인 코드 두 줄을 소개하자면
- 1. clientSocket = socket(socket.AF_INET, socket.SOCK_DGRAM)
- 2. clientSocket.bind((' ', 19157))
1번은 UDP 소켓을 생성하는 코드로
소켓이 생성될 때 트랜스포트 계층은 포트 번호를 소켓에게 자동으로 할당하고
2번은 소켓 생성뒤에 bind() 함수를 이용하여 특정 포트 번호를 UDP 소켓에 할당하기 위해 추가되는 코드이다.
2번은 옵션처럼 보이지만, 보통 bind 도 함께 쓴다.
코드를 적용시킨 예시를 보자
위 그림은 서버에 6428포트, 클라이언트 각각에 대해 9157, 5775 포트 번호를 적용해 소켓을 생성한 그림이다.
앞서 2.1 개념 밑에 있는 그림(뒤에 TCP에서 다시 등장합니다!)과 달리 서로 다른 데이터그램이 들어오는데도 불구하고
UDP에서는 목적지 IP 주소와 목적지 포트 번호가 같으면 2개의 세그먼트(데이터그램 내부의)들은 같은 목적지 소켓을 통해 동일한 프로세스로 향하게 된다. ( + 출발지가 다를지라도)
2.4 연결지향형 다중화와 역다중화
이번엔 TCP 다중화와 역다중화에 대해서 알아볼 것이다.
우선, TCP 소켓과 UDP 소켓의 차이점은 TCP 소켓은 4개 요소들의 튜플 (출발지 IP 주소, 출발지 포트 번호, 목적지 IP 주소, 목적지 포트 번호)에 의해서 식별된다는 것이다.
따라서 TCP 세그먼트가 호스트에 도착하면, 호스트는 해당되는 소켓으로 세그먼트를 전달하기 위해서 4개의 값을 모두 사용한다. (역다중화)
추가로 다른 주소 또는 포트 번호를 가지고 도착하는 TCP 세그먼트는 각기 다른 소켓으로 향하게 된다.
그림을 보고 이해하자
이들은 각각 출발지 - 목적지 간의 연결이 튜플 값에 따라 모두 다르게 되어있기 때문에
원하고자 하는 도착지에 세그먼트들을 옮길 수 있게 된다.
이러한 결과로 TCP의 연결 보장성을 확인할 수 있다.
3. 비연결형 트랜스포트 UDP
이번엔 트랜스포트 계층에서 UDP가 동작하는 과정을 자세히 살펴보겠다.
그 전에 UDP segment의 특징을 좀 더 자세히 보면
앞에서 계속 UDP의 특성 중 best-effort 라는 말이 나왔는데, 이 말은 UDP segment 가 갑자기 사라질수도 있고 전달 순서가 뒤바뀔 수 있다는 것을 의미한다.(1대1로 연결된게 아니기때문)
또한 이런 비연결형 특성때문에 handshaking 과정도 필요없게 된다.
3.1 UDP segment header
아까 위에서 봤던 UDP/TCP segment format에서 header field를 자세히 들여다본 그림이다.
UDP의 헤더 필드에는 length, checksum이 있다.
- length : UDP segment의 길이이며, 그림상 16비트지만 단위가 바이트이기 때문에 2^16= 약 65535 바이트라고 봐야 한다! 따라서 64KB이고 이 크기가 UDP 세그먼트가 보낼 수 있는 크기이다.
- checksum : 에러를 판별하기 위한 부분으로 바로 밑에서 자세히 설명하겠다.
3.2 UDP checksum
UDP 체크섬은 오류 검출을 제공한다. 즉 체크섬은 세그먼트가 출발지로부터 목적지로 이동했을 때
UDP 세그먼트 안의 비트에 대한 변경사항이 있는지 검사하는 것이다.
송신 측에서 UDP는 세그먼트 안에 있는 모든 16비트 워드를 더하고 이에 대하여 다시 1의 보수를 수행한다.
예를 들어, 다음과 같은 3개의 16비트 워드가 있다고 하자.
0110011001100000 -- 1
0101010101010101 -- 2
1000111100001100 -- 3
1과 2의 합은 다음과 같다
0110011001100000 -- 1
0101010101010101 -- 2
1011101110110101 -- 1 + 2
이에 3을 더한 값은 다음과 같다.
1011101110110101 -- 1 + 2
1000111100001100 -- 3
0100101011000010 -- 1 + 2 + 3
1과 1이 만나면 다음 자릿수로 넘어가는데, 자세히 보면 가장 왼쪽 비트는 갑자기 사라져 버렸다.
이는 오버플로우가 발생하여 가장 오른쪽 비트에 +1이 된 것이다.
다음은 1의 보수 과정이다. 합의 1의 보수는 다음과 같다.
0100101011000010 -- 1 + 2 + 3
1011010100111101 -- 합의 1의 보수
모든 1을 0으로, 0을 1로 바꾸면 되며 이것이 체크섬이된다.
따라서 체크섬을 포함한 4개의 비트를 더하면 값은 11111111111이 될 것이다.
이렇게 모든 비트가 1로 채워졌다면, 패킷에 오류가 없는 것이고
하나라도 0이 있다면 패킷에 오류가 발생했음을 알 수 있다.
4. 신뢰적인 데이터 전송의 원칙(rdt)
이번장에서 가장 이해하기도, 설명하기도 어려운 부분이다.
이번 장에서는 하위 채널 모델에서부터 신뢰적인 데이터 전송 프로토콜의 송신자, 수신자 측면을
점점 개발해나가면서 발생하는 오류들을 처리해나갈 예정이다.
자세한 설명에 앞서, 한 가지 가정과 용어들을 정리하자면
먼저 한 가지 가정은, 보내어지는 패킷들이 순서대로 전달된다는 것이다.
패킷의 순서를 바꾸지 않고 데이터의 흐름대로 설명할 것이다.
또한 용어들은 각각
- rdt_send() : 프로토콜의 송신 측은 이 호출에 의해 위의 계층에 의해서 호출이 된다.(call : 위에서 아래로)
- rdt_rcv() : 패킷이 채널의 수신 측으로부터 도착했을 때 호출된다.(callback: 아래에서 위로)
- deliver_data() : 수신자 측이 데이터를 반대로 넘길 때 호출된다.
- udt_send() : 비신뢰적인 데이터 전송(unreliable data transfer)으로서, 송신, 수신 측이 패킷을 양방향으로 전달할 때 사용될 것이다.
4.1 기본 그림
rdt 설명에 앞서 기본이 되는 그림을 하나 가져왔다.
이 그림은 FSM(유한 상태 머신)이며 화살표는 단방향(unidirectional)으로 동작하게 된다.
이 FSM에는 3가지 요소가 있는데 각각 state, event, actions이다.
- state : 각각 동그라미를 노드라고 보면, 노드 안에 쓰여 있는 글자들이다. 다음 이벤트를 결정하는 중요한 요소다.
- event : 전송이 일으키는 사건을 의미한다.
- actions : 이벤트가 발생될 시 취하는 행동을 뜻한다.
따로따로 설명하면 이해가 안 될 것 같아 먼저 설명하느라 서론이 길어졌는데, 이제 본격적으로 rdt에 대해 알아보도록 하자.
4.2 rdt 1.0 - 완전하게 신뢰적인 채널에서의 프로토콜
가장 이상적인 프로토콜로, 단순하며 따로 예외 처리해주지 않아도 된다.
하지만 이상일뿐 실제로는 존재하지 않는 프로토콜이다.
과정(sender)
- 1. 위에서부터 호출을 기다린다. (state)
- 2. rdt_send(data)로 상위 계층으로부터 데이터를 받아들인다. (event)
- 3. make_pkt(data) 데이터를 포함한 패킷을 생성한다. (actions)
- 4. udt_send(packet) 패킷을 채널로 송신한다. (event)
과정(receiver)
- 1. rdt_rcv(packet) 하위의 채널로부터 패킷을 수신한다. (event)
- 2. extract(packet, data) 데이터를 추출한다.
- 3. deliver_data(data) 데이터를 상위 계층으로 전달한다.
장점
- 오류가 생길 수 없어 수신 측이 피드백을 제공할 필요가 없다.
- 패킷 손실이 일어나지 않는다.
4.3 rdt 2.0 : 비트 오류가 있는 채널 상에서의 신뢰적 데이터 전송
rdt 2.0 은 비트 오류에 대한 해결책으로 재전송(retransmission)을 제시한다.
재전송을 하려면 수신자가 잘 받았는지 못 받았는지 말을 해줘야 알 수 있는데 rdt2.0에서는 수신 측의 피드백을 통해 이를 처리한다.
수신 측의 피드백
수신자는 ACKs 또는 NAKs를 송신 측에 전달하는데
ACKs는 잘 받았다는 의미이고, NAKs는 비트 에러가 발생했다는 의미이다.
1) rdt 2.0 : 에러가 발생하지 않는 상황에서의 작동
좌측이 sender, 우측이 receiver에 해당한다.
왼쪽 밑에 V를 거꾸로 뒤집은 모양은 이벤트가 발생했을 때, 아무런 액션도 취하지 않는 상태를 말한다.
과정(sender)
- 1. 위에서부터 호출을 기다린다. (state)
- 2. rdt_send(data)로 상위 계층으로부터 데이터를 받아들인다. (event)
- 3. make_pkt(data) 데이터를 포함한 패킷을 생성한다. (actions)
- 4. udt_send(packet) 패킷을 채널로 송신한다. (event)
- 5. isACK(rcvpkt) : ACK 피드백이 왔는지 확인한다.
과정(receiver)
- 1. rdt_rcv(packet) 하위의 채널로부터 패킷을 수신한다. (event)
- 1. notcorrupt(rcvpkt) 수신한 패킷의 손상 여부를 확인한다.
- 2. extract(packet, data) 데이터를 추출한다.
- 3. deliver_data(data) 데이터를 상위 계층으로 전달한다.
- 4. udt_send(ACK) ACK 피드백을 sender에 전달한다.
2) rdt 2.0 : 에러 시나리오
이번엔 에러가 발생해 NAK를 보내는 경우 과정이다.
과정(sender)
- 1. 위에서부터 호출을 기다린다. (state)
- 2. rdt_send(data)로 상위 계층으로부터 데이터를 받아들인다. (event)
- 3. make_pkt(data) : 데이터를 포함한 패킷을 생성한다. (actions)
- 4. udt_send(packet) : 패킷을 채널로 송신한다. (event)
- 5. isNAK(rcvpkt) : NAK 피드백이 왔는지 확인한다.
- 6. udt_send(sndpkt) : NAK 피드백이 왔으므로 재전송한다.
과정(receiver)
- 1. rdt_rcv(packet) 하위의 채널로부터 패킷을 수신한다. (event)
- 1. corrupt(rcvpkt) 수신한 패킷의 손상 여부를 확인한다.
- 2. udt_send(NAK) : 패킷이 손상되어 NAK 피드백을 보낸다.
- 3. rdt_rcv(rcvpkt) : 재전송된 패킷을 받는다.
- 4. extract(packet, data) 데이터를 추출한다.
- 5. deliver_data(data) 데이터를 상위 계층으로 전달한다.
- 6. udt_send(ACK) ACK 피드백을 sender에 전달한다.
위와 같은 과정은 고정된 과정이 아니라 여러 번 반복될 수도 있다!
4.4 rdt 2.0의 치명적인 에러들
- 애초에 ACK/NAK 피드백들이 손상된 경우 sender는 알 수 없다.
- 따라서 sender가 손상된 피드백들을 잘못 이해하여 재전송한 경우, 명령이(action) 복제될 가능성이 있다.
해결책 : 데이터 패킷에 새로운 필드를 추가하고 이 필드 안에 순서 번호를 삽입한다.
결과 : 순서 번호를 보고, 재전송된 것인지 새로운 패킷을 전송한 것인지 알 수 있다.
4.5 rdt 2.1
rdt 2.0의 수정된 버전이다.
rdt 2.1의 FSM은 전보다 두 배 많은 상태를 가지고 있는데, 이는 전송되거나 기다리고 있는 패킷이
순서 번호 0 또는 1을 가져야 하는지 반영해야 하기 때문이다.
순서 번호가 0 또는 1밖에 없는 이유는 두 가지 수만 반복해도 최근과 이전 패킷을 구분할 수 있기 때문이다.
1) rdt 2.1 sender's FSM
rdt 2.1의 FSM 그림이다. 2.0 버전과 달라진 점을 몇 가지 소개하자면
- 패킷에 0 또는 1이 추가되었다.(시퀀스 넘버)
- 상태가 2배 늘어났고, 이들은 각각 0 또는 1을 기다린다.
2) rdt 2.1 receiver's FSM
- has_seq# 함수가 추가되었다.
- 순서가 바뀐 패킷이 수신되면 수신자는 이미 전에 수신한 패킷에 대한 긍정 확인 응답을 전송한다.
- 수신자 FSM에서 make_pkt 함수에 chksum 인자가 추가되었는데, 이는 ACK 또는 NAK가 깨졌는지 여부를 송신자에게 알려준다.
이번엔 패킷이 복제되는 상황만 살펴보자면
- 1. 송신자가 데이터를 보냄
- 2. 수신자가 패킷을 잘 받았고, ACK 를 보냈으나 전송과정에서 NAK로 바뀌어버림 -> 이 상황에서 수신자는 seq1 을 기다리게끔 상태가 바뀌어짐
- 3. 송신자는 NAK를 받아서 다시 재전송하나, 수신측에서 seq가 안맞는걸 알고 바로 ACK를 보내줌
- 4. 송신자는 ACK가 왔으니 다음 상태로 이동
4.6 rdt 2.2 : a NAK-free protocol
rdt 2.2 버전은 rdt 2.1 버전에서 NAK을 사용하지 않은 프로토콜이다.
어떻게 NAK을 사용하지 않느냐면.. NAK 대신에 그 전 패킷에 대한 ACK을 보내는 것이다.
기존에 지금 패킷에 대한 NAK을 보내 재전송을 처리했다면, 지금은 그 전 패킷에 대해 ACK을 보내
수신자가 "저는 여기까지만 알아들었습니다!" 하고 그 이후의 패킷을 보내라는 의미이다.
rdt2.2의 FSM은 2.1 버전에서 NAK을 보내거나 확인하는 부분을 그 전 패킷에 대해 ACK을 보내거나,
현재 와야 할 ACK 번호가 올바르게 왔는지 체크하면 된다.
4.7 rdt 3.0 : channels with errors and loss
이전까지의 rdt 버전들은 비트 에러에 대해서만 처리했지, 패킷이 아예 유실되는 경우에 대해서는 처리하지 않았다.
만약 ACK이 유실되어 오지 않았다면, 송신자는 뭘 보내야 할지 도무지 알 수가 없다.
그래서 패킷이 손실되지 않고 제대로 갔는지 타이머를 통해 확인해야 하는데, 이 기법을 타임 아웃이라고 한다.
rdt 3.0 FSM sender
이번 FSM은 timer가 추가되었다.
타이머의 동작은 다음과 같다.
- 1. 패킷을 송신하는 시간에 타이머를 시작(송신측에서)
- 2. 만약 ACK가 오기 전에 타이머가 끝나면 재전송
- 3. ACK가 왔다면 타이머를 멈춤
하지만 패킷이 유별나게 큰 지연 시간을 가진다면 데이터 패킷이나 그 패킷에 대한 ACK가 손실되지 않았다 하더라도 패킷을 재전송할 수 있다. 이것은 송신자 - 수신자 채널에서 중복 데이터 패킷(duplicate)의 가능성을 포함한다.
하지만 우리는 이미 rdt 2.2에서 sequence number를 통해 중복되는 경우를 처리할 수 있다.
rdt 3.0 은 기능적으로 정확한 프로토콜이다.
하지만 이 프로토콜 역시 패킷을 하나하나 보내기 때문에 전송시간(RTT)의 문제가 있다!
4.9 Pipelined protocols
파이프 라인 프로토콜은 마치 송신자와 수신자 사이에 파이프를 연결하여, 송신자가 여러 개의 패킷을 마치 비행기를 타고 날아가는 것처럼 보내게 된다.
이 경우 여러 개의 패킷을 동시에 보내기 때문에 sequence number를 0과 1 뿐 아니라 여러개로 늘려야 하며
여러개의 패킷을 담을 수 있게 버퍼를 만들어 주어야 한다. 하지만 전송시간이 매우 빠르다.
보통 파이프라인 프로토콜은 두 가지 형태가 있는데, go-back-N과 selective repeat 기법이다.
1) go-back-N(GBN) : N부터 반복
GBN 프로토콜에서 송신자는 확인 응답을 기다리지 않고, 여러 패킷을 전송할 수 있다.
하지만 조건이 있다. 파이프라인에서 확인 응답이 안 된 패킷의 최대 허용 수 N보다 크지 않아야 한다는 점이다.
특징
- 송신자는 확인응답이 되지 않은 N개의 패킷을 파이프라인 안에서 가질 수 있다.
- 수신자는 받은 패킷들에 대해서 마지막 패킷에 대해서만 ACK를 보낸다.(누적 ack)
- 송신자는 가장 오래된 '전송되었지만 아직 확인 응답 오지 않은 패킷'에 대한 타이머만 사용한다.
GBN 프로토콜은 위 그림과 같이 직사각형의 윈도를 가진다. 이를 슬라이딩 윈도라고 한다.
가장 오래된 패킷의 순서 번호를 send_base로 정의하고, 사용되지 않은 가장 작은 순서번호를 nextseqnum으로 정의한다면, 순서 번호의 범위에서 4가지 패킷을 식별할 수 있다.
- 1. 이미 확인 응답받은 패킷
- 2. 전송하였지만, 아직 확인 응답받지 않은 패킷
- 3. 사용 가능하지만 아직 전송하지 않은 패킷
- 4. 사용할 수 없는 패킷
GBN의 중요한 특징
- 만약 base 패킷이 아닌 이후의 패킷에 대한 ack 응답이 먼저 왔다면, 그 이전의 패킷들은 모두 ack 처리한다.
- 만약 패킷 n+1이 먼저 도착했고, n이 수신되었는데 n이 손실되었다면(타임 아웃도 포함) n이상의 패킷들은 모두 재전송해야 한다.
2) Selective repeat : 선택적 반복
앞서 설명한 GBN의 특성 중 이전 패킷에 대한 손실이 발생하면, 쓸데없이 다른 패킷들도 재전송한다는 불필요한 액션을 한다는 것을 배웠다.
선택적 반복은 이러한 GBN의 단점을 보완한 프로토콜로, 오류가 발생한 패킷만을 송신자가 다시 전송함으로써
불필요한 재전송을 피한다.
문제점
위 그림처럼 만약 시퀀스 넘버가 3가지로 이루어져 있고, 윈도 크기가 3이라면
전송 중에 같은 시퀀스 넘버가 동시에 움직일 경우, 송수신자에게 혼란을 야기할 수 있다.
따라서 시퀀스 넘버는 적어도 윈도 크기의 2배는 넘어야 이 문제를 해결할 수 있다.
'Computer Network' 카테고리의 다른 글
| 7. TCP 혼잡제어 (0) | 2020.06.04 |
|---|---|
| 6. TCP - transport's view (0) | 2020.06.03 |
| 4. P2P, video streaming (0) | 2020.05.29 |
| 3. FTP, electronic mail, DNS (0) | 2020.05.28 |
| 2. application layer (2) | 2020.05.27 |