본 내용은 Computer networking : a top-down approach 책을 바탕으로 정리하였습니다.
Index
- 1. 소개
- 2. 가상 회선과 데이터그램 네트워크
- 3. 라우터 안에는 무엇이 있을까?
- IP : Internet Protocol
1. 소개
네트워크 계층은 우리가 앞서 계속 배워왔던 애플리케이션 계층 -> 트랜스포트 계층 다음으로 프로토콜 스택에 들어있는 계층이다. 네트워크 계층의 PDU는 datagram으로, 트랜스포트 계층으로부터 세그먼트를 얻어 각 세그먼트를 데이터그램으로 캡슐화하고, 인접한 라우터에게 데이터그램을 보내는 역할을 한다.
1.2 주된 기능
주된 기능은 데이터그램을 라우터에게 보내는 것으로, 이를 세분화하면 각각 포워딩과 라우팅이 있다.
1) 포워딩 : 패킷이 라우터의 입력 링크에 도달했을 때, 그 패킷을 적절한 출력 링크로 이동시키는 기능을 한다.
2) 라우팅 : 패킷을 이동시킬 때 경로를 결정하는 역할을 하며, 이러한 알고리즘을 라우팅 알고리즘이라 한다.
조금 헷갈릴 수 있으나, 포워딩은 라우터 내에서 어디로 갈지 결정하는 세부적인 요소이고,
라우팅은 라우터 하나가 아닌 전체 경로를 보고 경로를 탐색하는 것이라고 보면 된다.
1.3 포워딩 테이블
각 라우터는 자신의 포워딩 테이블을 가지고 있다.
라우터는 도착하는 패킷 헤더의 필드 값을 조사하여 패킷을 포워딩하는데, 그 전에 포워딩 테이블이 있어서
"만약 A라는 헤더값이 도착하면 B라는 출력 링크로 보내겠다"라고 이미 내정되어 있는 것이다.
1.4 연결 설정
네트워크 계층에서 포워딩과 라우팅 다음으로 중요한 개념으로, 주어진 출발지와 목적지 연결 내에서 네트워크 계층 데이터 패킷(datagram)이 흐르기 전에 출발지 -> 목적지까지의 경로에 대해서 라우터가 연결을 위한 핸드 셰이크를 하도록 요구한다.
1.5 네트워크 계층에 의해 제공될 수 있는 특정 서비스
패킷이 전달 될 때, 네트워크 계층에 의해 제공될 수 있는 특정 서비스는 무엇이 있는지 알아보자.
- 보장된 전달 (제한 지연 이내의)
- 순서화된 패킷 전달
- 보장된 최소 대역폭, 시간
2. 가상회선과 데이터그램 네트워크
네트워크 계층은 두 호스트 사이에 비연결형 서비스와 연결형 서비스를 제공한다.
-> 이 서비스는 네트워크 계층이 트랜스포트 계층에 제공하는 호스트 사이의 서비스이다.
두 서비스는 각각 데이터그램 네트워크, 가상 회선 네트워크라고 하는데 우선 둘을 비교해보자.
2.1 가상회선 네트워크(virtual circuit)
가상 회선은 말 그대로 회선(circuit)을 가장한 패킷으로, 연결성에 충실한다.
가상 회선은 다음과 같이 구성된다.
- 출발지와 목적지 호스트 간의 경로
- 각 링크마다 부여되는 가상 번호
- 경로상에 있는 각 라우터 포워딩 테이블 안의 엔트리
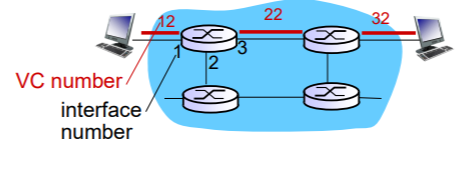
위 그림은 VC 포워딩 테이블에 따른 경로 탐색을 보여준다.
왼쪽 위에 있는 라우터의 포워딩 테이블에 "1로 들어왔고 12번 VC number면 3번 22 VC number로 나가라"라고 되어있으면 위 그림처럼 빨간색 경로로 이동하는 것이다.
이처럼 VC 포워딩 테이블은 라우터에 새로운 연결이 설정될 때마다 포워딩 테이블에 새로운 엔트리를 꾸준히 추가해야 한다. 이를 연결 상태 정보라고 한다.
2.2 데이터그램 네트워크
반면 데이터그램 네트워크는 아주 단순한데, 특성을 살펴보면
- 연결 설정이 되어있지 않다.
- 연결 상태 정보가 없다.
- 포워딩 테이블은 단순히 목적지 주소와 출력 링크로만 이루어져있다.
하지만 연결 상태가 유지되지 않기 때문에 패킷마다 경로가 달라질 수 있다는 단점이 있다.
또한, 목적지 ip 주소가 너무 많기 때문에 이를 처리하기 위한 방법이 필요하다.
2.3 Longest prefix matching
데이터그램 네트워크의 포워딩 테이블에서 많은 ip주소를 처리하기 위한 방법이다.
이 방식은 목적지 ip주소의 "가장 긴 접두사"를 찾아 각 링크 인터페이스에 보내는 방법인데
예를 들자면 이런 테이블을 가지는 것이다.
| dst addr | link interface |
| 11001000 00010111 00010*** ******** | 0 |
| 11001000 00010111 00011000 ******** | 1 |
| 11001000 00010111 00011*** ******** | 2 |
| otherwise | 3 |
만약 이 테이블을 갖는 라우터에 "11001000 00010111 00010110 10100001" 이 왔다면, 이 주소는
0번째 인터페이스로 향하는 주소와 *를 제외하고 모두 매칭 되기 때문에 0번으로 향한다.
반면, "11001000 00010111 00011000 10101010" 이 왔다면 1,2번 인터페이스와 모두 일치한다.
하지만 1번과 "더 길게 매칭되기 때문에" 가장 긴 접두사인 1번으로 향할 것이다.
3. 라우터 안에는 무엇이 있을까?
우리는 앞에서부터 계속 라우터는 패킷을 이동시키는 통로 같은 역할로만 보아왔다.
사실 그게 맞긴 하나, 정확히 어떤 방법으로 동작하는지 한 번도 알지 못했는데 이번엔 라우터가 정확히 어떤 구조로 이루어졌고, 어떻게 동작하는지 살펴보도록 하자.
3.1 라우터의 4가지 요소

- 입력 포트
- 스위칭 구조
- 출력 포트
- 라우팅 프로세서
3.2 입력 포트
입력 포트의 구성은 다음과 같다.
- 1. 물리적 계층(line termination)
- 2. 데이터 링크 처리(프로토콜, 캡슐화) ex) 이더넷
- 3. 검색, 포워딩, 큐잉
검색과 포워딩은 앞에서 본 것처럼 최장 접두사 매칭을 포워딩 테이블에서 찾고,
큐잉은 데이터그램 도착이 스위칭보다 빠른 경우 데이터그램을 큐에 쌓는 일이다.
3.3 스위칭
스위칭은 3.1의 그림에서 가장 큰 네모박스로, 라우터의 중심부 역할을 한다.
* switching rate : 입력에서 출력 포트까지 전송되는 속도를 의미한다.
스위칭의 3가지 예시
1) 메모리를 통한 교환
CPU 메모리가 직접 패킷을 제어해서 입력 포트와 출력 포트 사이에서 패킷을 스위칭하는 고전적인 방법이다.
패킷이 도착하면, 입력 포트는 라우팅 프로세서에게 인터럽트를 보내 패킷을 프로세서 메모리에 복사하게 된다.
이러한 작업은 데이터를 메모리에 쓰고, 그 메모리를 보내는 작업이 필요하기 때문에 속도가 제한된다.
2) 버스를 통한 교환
입력 포트는 라우팅 프로세서의 간섭 없이 패킷을 공유 버스의 출력 포트로 직접 전달한다.
이 버스 교환 구조는 링크 계층을 설명할 때에도 나올 것인데, 좀 흥미로워서 이해하기 쉽다.
예를 들어 1분 단위로 오는 버스를 생각해보자. 단, 이 버스의 탑승 인원은 1명이다. 그럼 택시 아닌가
모든 승객들은 하나의 버스를 통해 다른 정거장으로 가야 하므로, 승객들을 모두 만족시키려면 버스의 속도가 매우 빨라서 배차간격이 매우 짧아야 한다.
이처럼 버스 교환 구조도 승객을 하나의 패킷이라 생각하면 된다. 입력 포트에서 패킷은 버스를 타고 출력 포트로 갈 수 있다. 오직 패킷 하나만 한 번에 버스를 건널 수 있어 다른 패킷들은 기다려야 한다.
따라서 라우터의 스위칭 속도는 버스 속도에 의해 제한된다.
3) 인터커넥션 네트워크를 통한 교환
이러한 단일 버스의 한계를 극복하기 위해서는 더 복잡한 인터커넥션 네트워크가 필요하다.
인터커넥션 네트워크는 N개의 입력 포트와 N개의 출력 포트로 연결된 네트워크로서 마치 N X N 행렬처럼 구성된 스위칭 구조이다. 덕분에 입력 포트마다 처음에 있는 패킷은 바로바로 이동할 수 있지만 가격이 비싸다는 단점이 있다.
3.3 출력 포트
출력 포트의 구성은 입력 포트의 구성의 반대라고 생각하면 된다.
큐잉 -> 데이터 링크 처리 -> physical layer
- 맨 처음 큐잉은 datagram buffer를 이용해서 전송률보다 따르게 datagram이 도착하는 경우를 대비한다.
- 출력 포트의 결정은 출력 포트의 패킷 스케줄러가 전송을 위해 대기 중인 패킷 중 하나를 우선순위에 따라서 선택함으로써 이루어진다.
* 출력 포트 버퍼의 크기
-> 링크 전송률이 C이고, RTT가 주어진 경우, TCP stream의 양 N이 링크를 지나면 버퍼링의 필요량은
B = RTT x C(sqrt(N)) 이라고 한다.
3.4 HOL 블로킹 (input port queueing)
HOL(Head of Line) 블로킹은 동일 입력 포트 안에서 처리량 경쟁으로 인한 손실 발생을 의미한다.
예를 들어 동일 입력 포트 안에서 2번째 패킷은 갈 수 있으나 맨 앞 패킷이 대기하고 있어서 못 가는 경우를 의미한다.
1차선 도로에서 좌회전으로 갈 수 있는 신호인데 맨 앞 차량이 직진을 원해서 어쩔 수 없이 기다리는 상황이랄까..
4. IP : Internet Protocol
드디어! 네트워크 계층의 핵심인 인터넷 프로토콜에 대해 설명할 시간이다.

4.1 IP datagram format

인터넷 프로토콜의 헤더는 위와 같이 구성되어 있다.
여기서 중요시 봐야 할 것은 이후 등장할 IP fragmentation의 구성요소
(length, 16-bit id, flag, fragment offset) 4가지이다.
4.2 IP fragmentation
네트워크 링크는 MTU(최대 전송 단위)가 존재하기 때문에 datagram을 잘게 잘게 나눠야 하는데
이 작업을 fragmentation이라고 한다. 물론 나눴으면 합치는 과정도 필요한데, 이는 최종 도착지에서 이루어지며 reassembly라고 한다.
나눈 조각의 내부는 총 4가지로 구성되는데 이 구성이 아까 말한 IP fragmentation의 구성요소 4가지이다.
- length : 데이터의 길이를 말한다(단위 : 바이트)
- 16-bit id : 나중에 다시 합쳐야 하니 id가 필요하다.
- flag : 0 또는 1로 구성되어있으며 1이면 그다음 fragment가 있다는 것을 의미한다.
- offset : 각 fragment의 시작 Byte의 위치를 의미한다.
여기서 주의 깊게 봐야 할 것은 offset이다.
데이터를 나눈 후 재조립하려면 순서가 필요한데 offset이 그러한 역할을 해준다.
만약 4000 Bytes의 데이터를 3가지로 나눈다고 하자. (보통 이더넷은 1500byte가 최대 전송량)
1500, 1500, 1000으로 나눈다고 할 때, 보통 앞의 20바이트는 datagram의 헤더가 차지하므로
각 fragment의 offset은 (0, 1480, 2960)이 될 것이다.
하지만 offset의 크기는 1바이트뿐이므로 이를 8로 나눠 저장한다. 따라서 offset은 각각 (0, 185, 370)이 된다.
(맨 앞은 항상 0입니다!)
4.3 IPv4 주소체계
간단하지만 아주 중요한 내용이다!
IP 주소체계를 살펴보기 전에, 호스트와 라우터가 네트워크에서 연결되는 방식에 대해 한 가지 단어를 정리할 필요가 있다.
우선 호스트 IP가 데이터그램을 보낼 때, 물리적 링크 사이에서 인터페이스를 통해 보낸다.
인터페이스는 각 링크마다 하나씩 가지므로, 라우터는 여러 개의 인터페이스를 가진다.
추가로 각 인터페이스는 독립적인 IP 주소를 가지는데, IPv4에서 IP 주소의 길이는 4바이트로 약 40억 개의 가능한 IP주소가 있다.
IP 주소 구성
IP 주소는 네트워크 주소(network ID) + 호스트 ID로 구성되는데 이 둘의 길이는 호스트 ID 개수의 필요에 따라 나뉜다.
예를 들어 우리 학교 같은 경우는 학교가 아주 작기 때문에 8비트 정도의 호스트 ID 개수면 충분하지만,
아주 큰 기업 같은 경우는 24비트 정도는 필요할 것이다. 이를 제외한 나머지는 네트워크 주소가 차지하게 된다.
서브넷
하지만 이런 IP 주소들을 마음대로 정하면 잔챙이(남는 IP주소)들이 너무 많이 생겨버려서
그룹 별로 묶어 저장하게 되는데 이 그룹을 서브넷이라고 한다.
따라서 서브넷은 IP 주소에서 네트워크 영역을 부분적으로 나눈 부분 네트워크를 뜻한다.
일반적인 라우터와 호스트를 연결한 시스템에서 서브넷을 정의하기 위해 다음과 같은 방법을 사용할 수 있다.
"서브넷을 결정하기 위하여, 먼저 호스트나 라우터에서 각 인터페이스를 분리하여 고립된 네트워크를 만든다.
이 고립된 네트워크의 종단점은 인터페이스의 끝이 된다. 이렇게 고립된 네트워크 각각을 서브넷이라고 부른다."
서브넷 마스크
서브넷을 만들 때 쓰이는 것으로 IP 주소와 같은 32bit의 형태를 가진다.
이 서브넷 마스크의 목적은 IP 주소와 AND 연산하여 호스트 ID 내에 있는 서브넷 주소를 걸러내려는 것인데,
예를 들어 IP가 123.12(서브넷).12.1 일 경우 서브넷 마스크가 255.255.0.0이다.
이 둘을 AND 연산할 시 123.12.0.0 이 되는데, 이것이 이 IP의 네트워크 ID가 되며 이를 역으로 취할 경우 서브넷의 크기(호스트의 개수)가 된다.
또한 IP주소 중 뒤에 /24 따위가 붙은 것을 볼 수 있는데 '/' 뒤에 있는 숫자는 서브넷 주소의 길이를 의미한다.
서브넷 마스크가 255.255.0.0이라면 이는 초기 16bit가 1로 되어있기 때문에 IP는 123.12.12.1/16이 되는 것이다.
4.4 CIDR(classless introdomain Routing)
사이더는 클래스 없는 도메인 간 라우팅 기법으로 나름 최신의? IP 주소 할당 방법이다.
이는 기존 네트워크 클래스를 대체한 방식으로 유연하다.
A.B.C.D/N과 같은 형태로 구성되어있으며 IPv4 주소와 마찬가지며 N은 접두어 길이를 가리킨다.
만약 처음 N 비트의 IP 주소와 사이더 접두어가 같다면, "일치한다"라고 한다.
사이더의 장점은 사용되지 않은 32-N 비트의 주소를 남겨 남은 비트로 2^(32-N) 개의 조합을 구할 수 있다는 점이다.
만약 우리가 1000개의 IP주소가 필요하다 하면, 1000은 2^9 ~ 2^10 사이에 존재하므로 32-10 비트의 주소를 남기면 되는 것이다. 이것만 봐도 상당히 유연하다고 볼 수 있다.
이런 장점은 라우터들에게 포워딩 테이블의 크기를 상당히 줄여주게 된다.
'Computer Network' 카테고리의 다른 글
| 10. 라우팅 알고리즘 (2) | 2020.06.09 |
|---|---|
| 9. DHCP, NAT, IPv6 (0) | 2020.06.09 |
| 7. TCP 혼잡제어 (0) | 2020.06.04 |
| 6. TCP - transport's view (0) | 2020.06.03 |
| 5. Transport layer (6) | 2020.06.02 |